Ever Have to Combine CSVs? Do It Better With Python Pandas!
Using the Python Pandas Library to better manipulate row and column data, I recently conducted research on a variety of websites to compare engagement rates. My findings included 15 visitors and a 1% engagement rate for Netflix.com, and 20 visitors and a 2% engagement rate for IMDB.com. Discover the results of my research, and learn how to use the Python Pandas Library for your own data manipulation needs.
Combining Multiple CSVs Easily with Python Pandas: Discover My Research Results!
By Michael Levin
Tuesday, April 18, 2023
You need something that you can get better at forever. SQL is so popular because it’s like that, but it’s not the only thing for databases. Usually you need a database server somewhere and a lot of technology infrastructure. It’s not a particularly on-the-fly or ad hoc technology. But this is available for database work, especially in the Python world. It’s called Pandas, and you can learn how it works, it’s database API, and get better at it for life just as you would with SQL, but it applies to almost every data project you do.
That’s how you bring craftsmanship to tech. Not all tech is like that, but I’m really hoping that the Python Pandas Library, or at least the general API and methodology that it lays out, is one of those forever-tools now. It has entered the ranks of SQL as a way to manipulate row & column data. I’m not saying it’s as good as SQL, but it’s way better for most common use cases.
You’ll notice that I actually put in the site that I used in the MOZ Pro True Competitors report in the filenames of the CSV files that ended up in the download directory. If I didn’t, there’d be no way to tell what the original query was. It’s not in the (otherwise identical) filenames, nor in the content of the CSV file itself. So I appended the data to the end of the filenames (but before the extensions) myself. And we have to use that data.
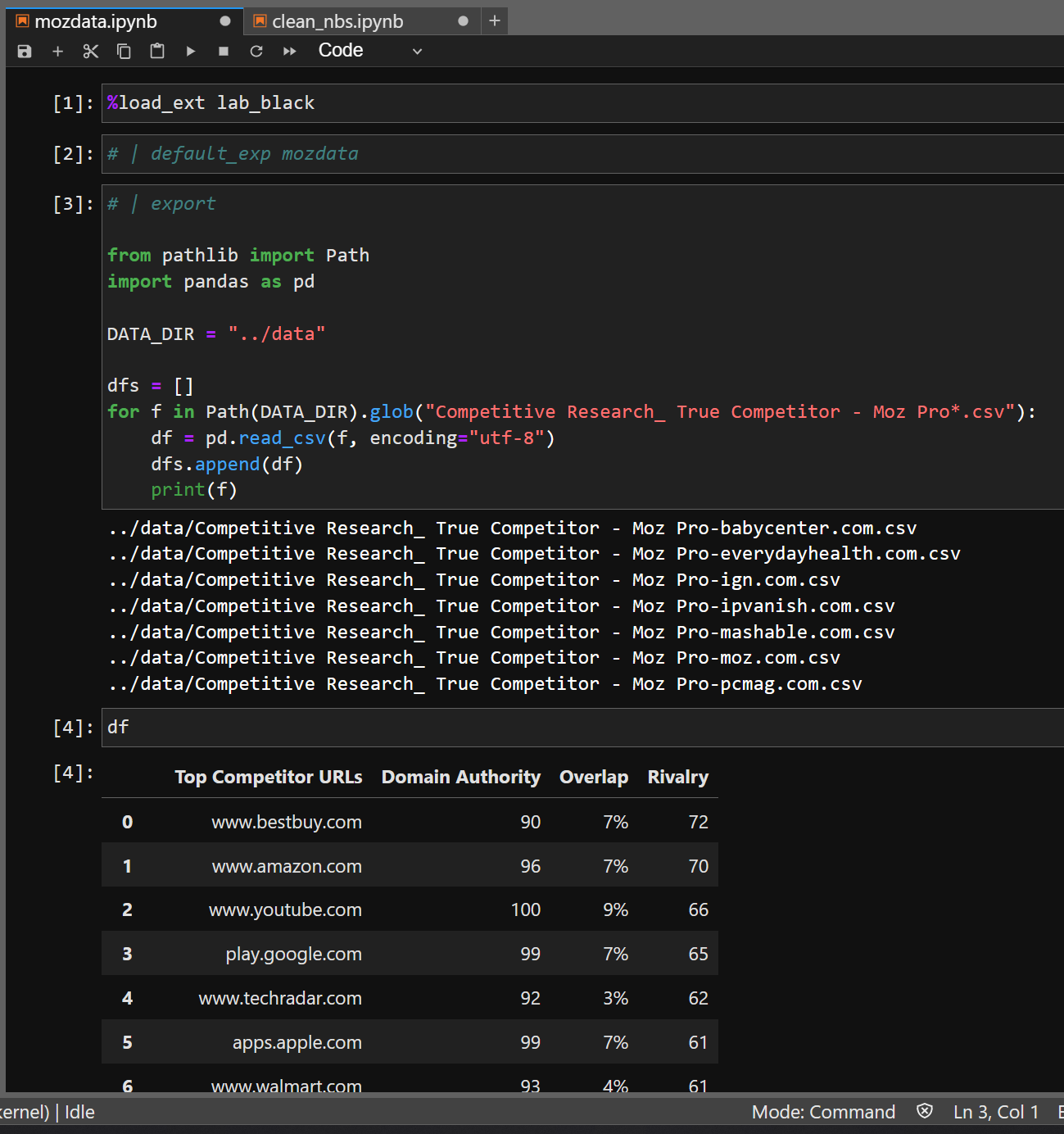
Let’s find those site-names embedded into the filenames. Here’s us parsing out the site name:
from pathlib import Path
import pandas as pd
DATA_DIR = "../data"
dfs = []
for f in Path(DATA_DIR).glob("Competitive Research_ True Competitor - Moz Pro*.csv"):
fname = f.name
site = fname.split()[-1][4:-4]
print(site)
df = pd.read_csv(f, encoding="utf-8")
dfs.append(df)
…and this is all it takes now to have a “Competitor” column, so you know who each of the rows was chosen as a “true competitor” for:
from pathlib import Path
import pandas as pd
DATA_DIR = "../data"
dfs = []
for f in Path(DATA_DIR).glob("Competitive Research_ True Competitor - Moz Pro*.csv"):
fname = f.name
site = fname.split()[-1][4:-4]
print(site)
df = pd.read_csv(f, encoding="utf-8")
df["Competitor"] = site
dfs.append(df)
df.head() produces:
Top Competitor URLs Domain Authority Overlap Rivalry Competitor
0 www.bestbuy.com 90 7% 72 pcmag.com
1 www.amazon.com 96 7% 70 pcmag.com
2 www.youtube.com 100 9% 66 pcmag.com
3 play.google.com 99 7% 65 pcmag.com
4 www.techradar.com 92 3% 62 pcmag.com
With this one tiny change, you now have all the dataframes combine, stacked vertically as if you pasted a bunch of CSV files together top-to-bottom. In Pandas parlance, they call this concatenation. In SQL parlance, this would be closer to a union. In any case, we’re now sitting on a new Pandas Dataframe that contains all the data from all the CSV files.
from pathlib import Path
import pandas as pd
pd.set_option("display.width", 1000)
DATA_DIR = "../data"
dfs = []
for f in Path(DATA_DIR).glob("Competitive Research_ True Competitor - Moz Pro*.csv"):
fname = f.name
site = fname.split()[-1][4:-4]
df = pd.read_csv(f, encoding="utf-8")
df["Competitor"] = site
dfs.append(df)
df = pd.concat(dfs)
print(df.sample(20))
Produces:
Top Competitor URLs Domain Authority Overlap Rivalry Competitor
15 www.imdb.com 95 1% 55 mashable.com
19 www.instagram.com 94 1% 49 ign.com
5 www.hulu.com 89 3% 60 ign.com
15 www.netflix.com 93 1% 50 ign.com
20 www.imdb.com 95 2% 44 babycenter.com
18 www.cancer.gov 85 1% 41 everydayhealth.com
23 www.cdc.gov 94 1% 43 babycenter.com
20 developer.mozilla.org 97 2% 46 moz.com
5 www.verywellfamily.com 71 10% 59 babycenter.com
14 www.businessinsider.com 94 3% 52 pcmag.com
23 www.popularmechanics.com 89 1% 39 ipvanish.com
7 www.healthline.com 88 5% 52 babycenter.com
2 blog.hubspot.com 93 9% 68 moz.com
8 developers.google.com 95 6% 60 moz.com
7 www.techopedia.com 73 1% 49 ipvanish.com
4 support.ipvanish.com 72 1% 51 ipvanish.com
14 blog.hubspot.com 93 1% 56 mashable.com
0 www.whattoexpect.com 76 14% 74 babycenter.com
16 www.tomsguide.com 89 2% 51 pcmag.com
4 www.pampers.com 66 11% 61 babycenter.com