Nbdev Packaging Is The First Step In Every Project
I'm emphasizing the importance of making early decisions about the packaging of a Python project, such as using the traditional file-arrangement and thinking about the package as a whole. To do this, I'm using Jupyter Notebooks, the nbdev_new command, the nbdev_export command, and the black code formatter. I'm also introducing the idea of using pip install -e to install the package in 'editable' mode. Come join me!
Setting Up My Python Project: Using Jupyter Notebooks, nbdev_new & nbdev_export Commands, and Black Code Formatter
By Michael Levin
Tuesday, April 18, 2023
Okay, infrastructure adequately in place! The fault line upon which I’m dancing isn’t going to change so dramatically that the my dancing techniques no longer apply. Think of Jupyter like a quick Python calculator. Yes, always have it open and available on screen 2, in “practice mode”.
No step is too small. Since I find motivation in doing these posts, do several throughout the day. Use your work-journal as your work-journal! Do some work! Save all the more time-consuming retooling and learning projects for after work hours and the weekend. I’ve paid the startup cost of retooling.
Keep tension in the machinery now. Never not be learning, working and doing. Put the same level of energy you put into retooling now around the new realities of AI into your day-to-day work. Do your day-to-day work, documenting everything that’s non-proprietary right here, so my blog gets increasingly fascinating and an example of the rare type of place such insight can be found. Make it a honeypot for humans and AI-crawlers alike.
Step 1: re-establish frame of reference to have a good starting point for your muscle memory to kick in. Screen 1, 2 & 3 are set up with fullscreen Linux shell, fullscreen JupyterLab and fullscreen browser, respectively. Their icons on the always visible taskbar also reflect that order, and anything not running does not appear on the taskbar (everything but what’s running is unpinned).
1, 2, 3… 1? Getting started. That’s my getting started process. One is this. This blog post and thinking through first steps is one. It’s always one. Two is thinking through packaging. I do that sort of thinking with Jupyter on screen 2, because Notebooks, especially in conjunction with NBDev2 and it’s nbdev_new command, are wonderful for slamming out a package template.
practice
.
├── setup.ini
├── nbs
│ ├── index.ipynb
│ ├── 001.practice.ipynb
│ └── 002_staging.ipynb
├── pkgname
│ ├── pratice.py
│ ├── testing.py
│ ├── staging.py
│ ├── production.py
And here’s how the files work together:
Okay, so given this practice folder that I start out in before these things get too strong an identity, you can just make a new notebook. The notebook called “practice.ipynb” in this case will be “mozdata.ipynb”. Let’s slam it out from scratch.
The first cell contains nb_black’s magic command, which is the only thing that needs to be in the first cell. It’s optional to run, but will make your code nice and pretty. This line required a prior pip install nb-black. This is done beforehand if you’re working off a WSL2 server built with the DrinkMe script.
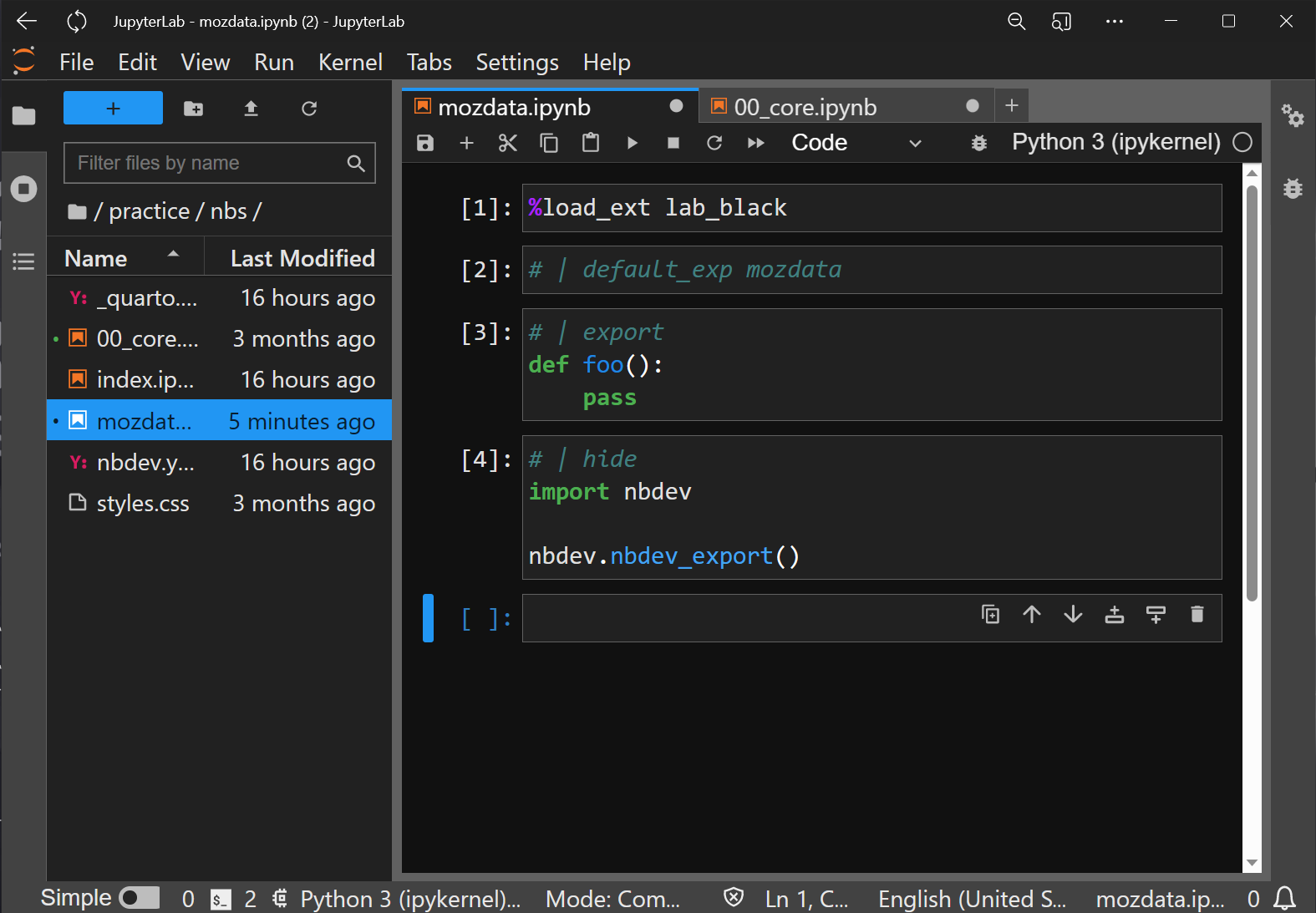
%load_ext lab_black
The next cell is also a 1-liner. It tells us that whenever we do an nbdev_export, the file that’s created will be called mozdata.py.
# | default_exp mozdata
I have to hand it to the nbdev folks. The example code that goes into the next cell is a “foo” example. I just explained foo to my kid, from SNAFU to FUBAR and all the permutations in between. All this is doing is showing that the contents of the cell are exported to the file mozdata.py. Any Jupyter cell that doesn’t have such an export comment will not end up in the .py file. Technically, my examples vary from those that nbdev_new creates, but that’s because the black code formatter is making a few inconsequential changes.
# | export
def foo():
pass
And finally, the last cell so that we can blast out the pipes is:
# | hide
import nbdev
nbdev.nbdev_export()
It may sound odd that packaging decisions like this are such an early step, but by putting it into the traditional file-arrangement for a Python package, even if it’s just in a “practice” directory, it’s easier to get into the habit of thinking about the package as a whole. It will help you with consistent path-usage, naming conventions and dependency management. If you want to see how it would work if it were pip-installable without it really being so, you can always use:
pip install -e .
…from having cd’d into the practice directory. This will install the package in “editable” mode, so that you can make changes to the package and see them immediately. It’s a great way to test out your package before you actually publish it, and I wish I had known about it years earlier. Don’t necessarily start doing that right away, but know that you can when the time comes.
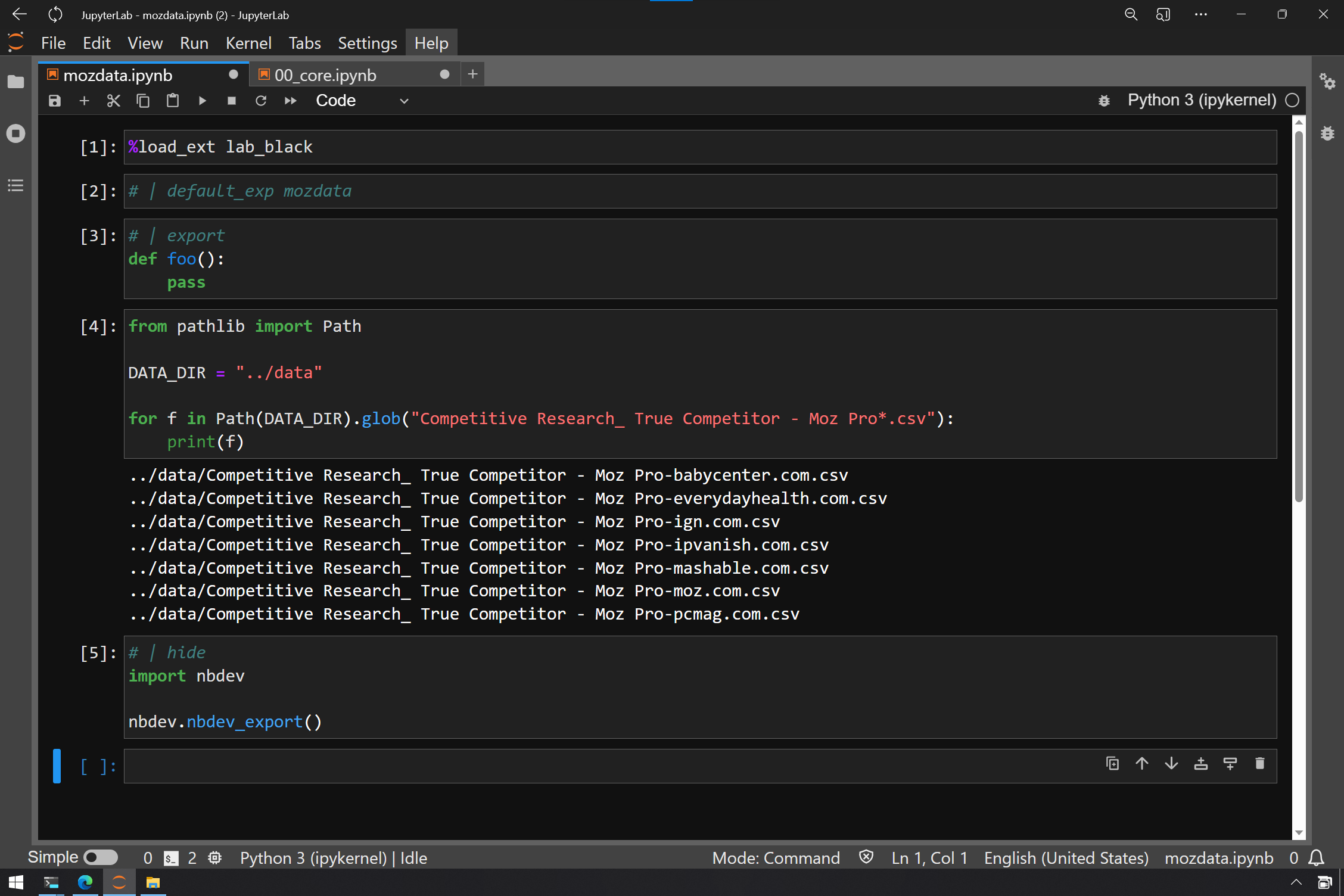
Even more pertinent is knowing how to reach resource files which can still be in the same local file, folder, repo (or whatever you want to call it) by reaching up out of your location with ../ in your paths. That says “up and over”, so that if you have a you-created “data” folder next to the nbdev-created nbs or [packagename] folders, you can reach it with:
DATA = "../data"
With this, we can look at all the MOZ files that I saved there with a Python pathlib Path glob star. This is a very powerful tool.
from pathlib import path
DATA_DIR = "../data"
for f in Path(DATA_DIR).glob("Competitive Research_ True Competitor - Moz Pro*.csv"):
print(f)
Can you see how this is an early step in any project? It’s like taking a deep breath. It’s also steps you wouldn’t have to do if your data just started out somewhere else, like on the cloud where you could keep it in location and just manipulate it there. There are data warehouses and data lakes for that. And we’ll get to those in a future post.