Python Pandas Dataframes vs SQL in Snowflake Data Warehouse
I've been working with SQL since the 90s and discovered the power of Python Pandas Dataframes around 10 years ago. Today, I'm surprised to find Snowflake Data Warehouse makes expensive use of Python, and am very happy that that Dataframes are shaping up to be such a mainstream data API alternative to SQL.
Discovering the Benefits of Python Pandas Dataframes and Snowflake Data Warehouse for Joining Data from Disparate Sources
By Michael Levin
Monday, May 8, 2023
I’m an old Microsoft SQL Server guy. I was on SQL Server version 6 back in the mind-90s, which was effectively version 1 as it broke off from Sybase, and you couldn’t even rename field names with a database table without recreating the entire table. I was stuck on it for a few years, as the cost to upgrade to 6.5 which was worlds better with the basic baseline features was not deemed something I needed.
Those were some painful days. We were a Microsoft shop, but it almost drove me to Linux and MySQL so I could have a little control, but after about few years of petitioning, I finally got the upgrade to 6.5. That was my initial SQL experience, and I did some wonderful things with that and Active Server Pages (.asp files) with the Active Data Object (ADO) library. That’s what I learned SQL and Microsoft’s dialect of Transact SQL (T-SQL), with it’s “theta” joins and a bunch of non-standard proprietary SQL extensions that were not ANSI SQL compliant. Microsoft was making me a Microsoft guy.
I moved on from there over time to SQL Server personal edition, and even used Microsoft Access from time to time for “local” web dev. This was long before the cloud, and whenever you wanted to do something interesting that didn’t hit the company’s main tech infrastructure, you had to create a “local” database and do your work there. It never lasted long on a local system because of the dynamic day-to-day nature of laptop hardware, and I didn’t particular have nor want a home network in those days. So there was a lot of spinning up whole local database infrastructures as you needed them, even for lightweight tasks. More pain.
Over time I found my way to Python and Pandas dataframes where you don’t need any of that local tech infrastructure (no installed database, for example) to do ad hoc work. You’re not even spinning up a database in the case of Pandas dataframe, but rather working with the data in-memory doing all the same joins, unions, filters and aggregates that you would do in a database. It doesn’t have the same “CRUD” (Create, Read, Update, Delete) API approach, nor would you want it because by that time you should just be using a real database. But so long as you weren’t like doing web development work and were doing more ETL (Extract Transform Load) work, it was a great way to go. No tech liability!
But in such scenarios, you are bound to the capabilities of your local hardware still, and with most Pandas dataframe stuff being in-memory, you could really tap out the size of the jobs you could do pretty quickly. Your source data could become too big, or the memory and processing requirements of the data transforms you were trying to do could become too big. It was about half the solution, and one of the great things though was giving up the old SQL dialects in favor of the Pandas dataframe API. As popular as SQL is, Pandas dataframes is just a much more natural way to work for me. And I’m not alone.
So that took you from like 25 years ago in the halls of Scala Multimedia (later Digital Signage) circa 1996 up to about 2015 when I took up Linux, Python, vim & git as my new platform for life. The transition started around 2009 with my kid on the way and tech fatigue from planned obsolescence striking me so deeply that I was in a state of revolt from the proprietary stuff.
I was also approaching the free and open source software (FOSS) with a fair degree of skepticism, especially on the database front. MySQL was gobbled up by Oracle in this time, so even the safest of safe harbors were not so safe. I came to Pandas dataframes slowly, and it wasn’t until a good 5 years into Python before I was won over by the Jupyter Notebook and Python pandas-based Data Science revolution. And a revolution it was. Revelations and revolutions.
That there were better data-APIs than SQL out there was quite a revelation. I mean it’s like saying there’s better HTML out there. Oh wait, there is. It’s called Markdown. But better doesn’t always win, so when something’s trying to compete with the most popular technology in the world and like the #1 keyword to appear on your resume and such (SQL), it had better be a lot better.
Today, I’m really delving into the Snowflake data warehouse and marketplace website. You can keep your own data from disparate sources there and do SQL-like joins across data from different systems that you would not normally be able to do with a traditional SQL database. It’s a data warehouse, meaning that no matter where else your data lives, it can also live in Snowflake to give you a single place to query it all.
As a marketplace, it also brings a lot of data from other companies to your fingertips, at a price usually for anything more than the sample data that serves a marketing purpose. But it’s a great way to get started with a new dataset, and get a feel for the data and what it can do for you. If you buy the bigger datasets, you’ll already know the schemas from the sample. You can even design your sample queries against the sample data, and then just change the table names to the real ones when you buy the data.
After I distanced myself from the proprietary stuff and the tech liability of local database installs, I never really dove into the cloud databases. I figured they were pretty much out of my future and on those rare occasions I needed local database capabilities, I would just use the SQLite database that comes with Python. I didn’t even use SQL with it most of the time, but instead used Python libraries like sqlitedict to use almost exactly the same API as the Python dict datatype. You simply had to use it in the context of the Python “context manager” and it would do all the database stuff for you like opening and closing connections. It’s bliss.
But as a technology generalist, the time will come when you have to learn something new, and that time is now. I’m learning Snowflake. It has echos of the SQLServer days, but it’s a lot more like the cloud databases of today. There’s new paradigms to learn, and while they’re proprietary, it’s not a whole vendor lock-in strategy, like the days of Microsoft and Oracle. It’s just another website which has the typical UI nuances you have to get used to. And here are some of the things I’m learning.
You enter Snowflake with a PUBLIC role and the inability to access almost anything. What’s worse is if you’re in the “old” user interface and you start getting used to stuff that’s going to all be different almost immediately. I didn’t see the change to the new user interface until after I had a “role” assigned to me that allowed me to do things. And in this case, it was ACCOUNTADMIN.
Okay, with the right role set I see a primary navigation devices running accordion-style down the left side of the screen. The other navigation at the top of the screen changes based on that, so that’s secondary nav.
Almost everything I want to do appears to be in the “Worksheets” section of the primary nav. I can create a new worksheet from a little plus sign at the top right of the screen. It’s actually pretty easy to overlook, but when you use it, you can choose between making a “SQL Worksheet” or a “Python Worksheet” or a folder. Looks like I bet pretty well on Python, huh? Even in a high falutin data warehouse, Python is the language of choice.
Okay, so I’m making one worksheet of each type. I did the SQL type at first and
did the basic select count(*) from table query to see how many rows are in
the table. It’s small. I try doing some other rudimentary SQL stuff, and I
realize why I prefer Python pandas so much, so I close that worksheet,
hopefully never to be open again. Now I go to the Python worksheet. I can’t
wait to see the implementation.
I am met with what looks like an online Python execution environment. No, it doesn’t look like Google Colab or Azure Notebooks or anything like that trying to emulate the whole Jupyter Notebook experience. Nice and simple. Let’s hit run!
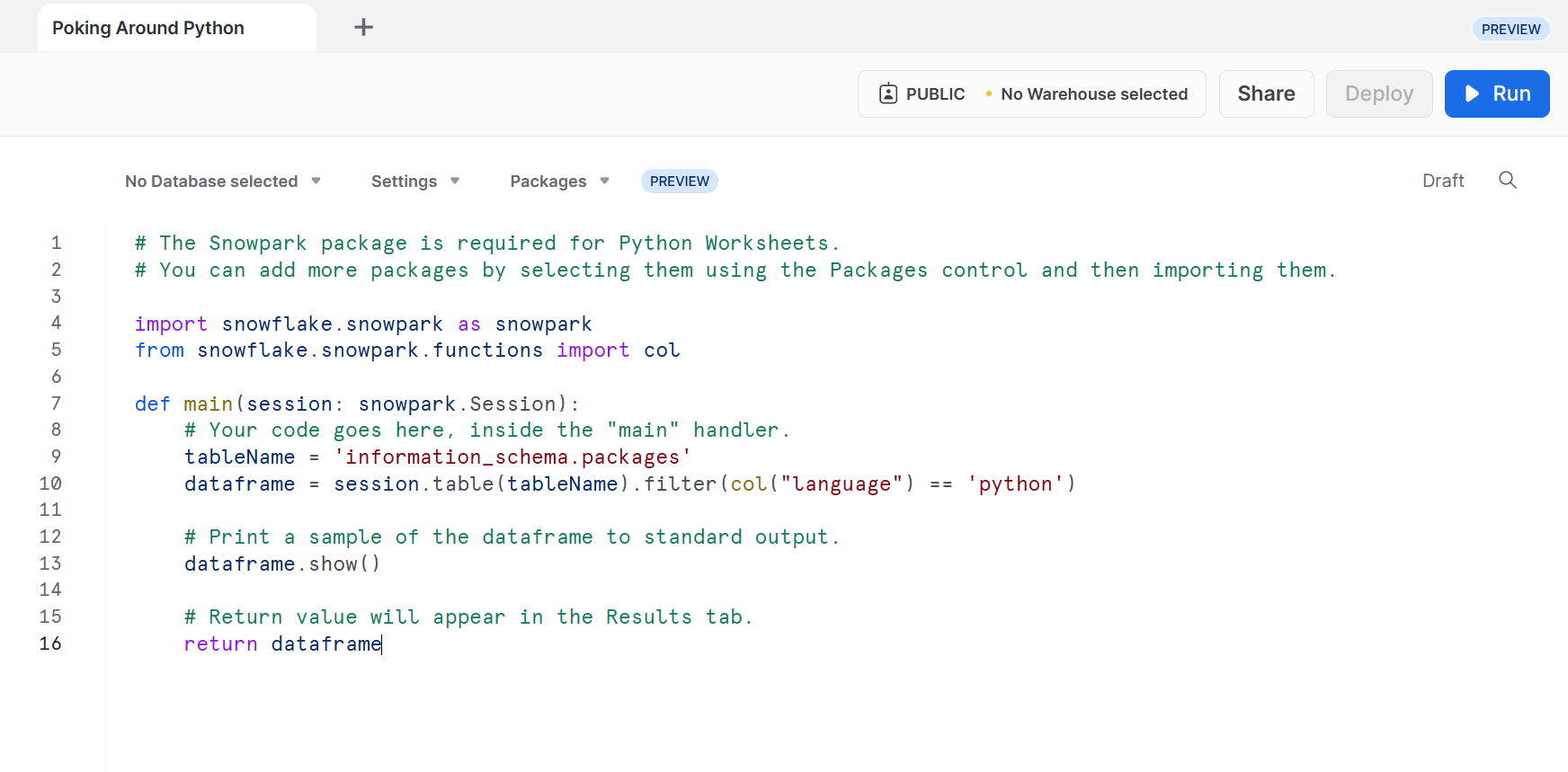
Nothing. Oops, when starting a new Worksheet, you have to switch your role to ACCOUNTADMIN again. It’s on a per Worksheet-tab basis. Yep, when I’m in the right role, I get 5,179 rows, which is odd because the Python code doesn’t look like it’s even calling the function.
# The Snowpark package is required for Python Worksheets.
# You can add more packages by selecting them using the Packages control and then importing them.
import snowflake.snowpark as snowpark
from snowflake.snowpark.functions import col
def main(session: snowpark.Session):
# Your code goes here, inside the "main" handler.
tableName = 'information_schema.packages'
dataframe = session.table(tableName).filter(col("language") == 'python')
# Print a sample of the dataframe to standard output.
dataframe.show()
# Return value will appear in the Results tab.
return dataframe
So the outputting of the table, which I bet cost something, is either a side
effect of those imports or the Snowflake system is rigged to run the contents
of a function called main automatically. Either way is funky and non-standard
and I don’t like it.
Okay, it says you can download it as a CSV or Excel file, and so I did. Ah, it’s a list of optional Python packages you can import. Okay, good to know. File that away for later.
Ooh, yuck! That’s full of proprietary. And any research into Python snowflake leads to local Jupyter Notebook / Snowflake integration.
Ugh, okay. I need to sharpen my knife. Before doing anything more that “runs queries” and potentially costs (too much experimenting to just get the basics!), see what you can do with just the Web UI and menus. Poke around tables and schema. That sort of stuff used to be so easy!
Okay, this is something that definitely must be done from the context of a Worksheet. You need a worksheet to have access to any sort of object explorer.
Once you’re in a Snowflake worksheet, there’s a “modal switch” between
Databases and Worksheets in the primary nav. That’s weird. It’s already a
strange UI mechanism in primary nav, but okay. Worksheets are for what appear
to be sub-worksheets within worksheets. So there’s Worksheets/Worksheets. Fine.
But to poke around tables and schemas, you switch to Databases and then drill
into a database called PUBLIC. As with SQLServer, just because it’s labeled
PUBLIC doesn’t mean the public can see it. This is a really awful convention of
the database industry. I guess they’re using familiar conventions.
Okay, I new feel I have the lay of the land. I can see the tables and schemas
and I can do the standard select count(*) from table to see how many rows are
in a table. They use the more ANSI-standard select * from table limit 10 to
just get N-rows than the Microsoft select top 10 * from table which is a good
sign.
Okay, so the Python stuff is looking too proprietary from within their Web interface to appeal to me. I will give it some more chance to win me over.
But I think my next step is going to be the actual Jupyter Notebook integration like in that video. That’s looking pretty appealing.
This is not the end of the story. This should evolve into one of those things where good API-choices become the gift that keeps on giving. I was a little disappointed in the proprietary nature of the Python integration through the Web UI, but even their own video examples are not using that, but rather is using a genuine Jupyter Notebook. But I ran out of steam for today.
To be continued.