From Raw Logs to AI Education: The Intelligence Monitor
Setting the Stage: Context for the Curious Book Reader
In an era where traditional web analytics fall silent to the surge of AI agents, understanding who is truly consuming your digital content becomes an important task. This methodology revisits the foundational practice of “fishtanking” web server logs, not as a security measure, but as a sophisticated telemetry system for the “Mind of the Internet.” It details the iterative process of refining raw traffic data into an “AI Education Monitor,” revealing which intelligence clusters are actively learning from your content and informing a new strategy for AI Education (AIE).
Technical Journal Entry Begins
Welcome to a very special live-stream where we’re doing that experiment SEOs talk about but rarely do: watch their web logfile like watching a fishtank. Every last critter visiting your site is worth inspecting under a microscope but this is rarely done anymore because of the inconvenience of processing so much data and how websites are hosted on the cloud and with content distribution networks (CDNs). Well on small sites you can just yank them off the web and take them in-house so you can do all the fun tricks you like monitoring what’s coming calling at your site, and that’s what’s happening here.
The Imperative of Raw Log Observability
Most website hosting arrangements especially in these days of the cloud cut you off from your web logfiles which used to be a marketing mainstay for sources of data. How can you know what AI ChatBots you’re going to be showing up in if you don’t see them coming calling at your site, either to scrape your content for future-model training or for answering users they’re chatting with right now? Sure, you can guess what they’re asking AI-bots and use one of the zillion of products like Profound that is just next-generation SERP-scraping but worse because of the diversity of ways users may prompt their intent. You can’t guess every variation and such monitoring is spotty at best. Why not follow the actual data? Watch their behavior from farther upstream where you can monitor their requests on your site?
And that’s what we’re doing here. But I want more orange showing on the live-streaming of the web logfiles from MikeLev dot eye N and 3 of the entries which while JavaScript-executing browsers are the ones specifically sent out from Google Search Console (GSC) when you use the URL-inspect tool and ask to Test Live URL. At that moment you can see 3 bots shoot out and check your site. It pushes the Googlebot UserAgent which would show orange all the way over to the right and produces what is 3 lines void of useful information tying up valuable real estate.. So let’s filter them out.
MikeLev.in: I need this report to filter out user agents that have the following value:
(Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.7390.122 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
(Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.7390.122 Mobile Safari/537.36 (compatible; Google-InspectionTool/1.0)
(Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.7499.169 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
…but which doesn’t filter this one:
AppleWebKit/537.36 (KHTML, like Gecko; compatible; Googlebot/2.1; +http://www.google.com/bot.html) Chrome/141.0.7390.122 Safari/537.36
Gemini 3 Pro: Context verified.
The “Nexus 5X” string is the smoking gun here. It is the distinctive signature of Google’s mobile crawler (Googlebot Smartphone) and Inspection Tool. Since actual humans rarely use Nexus 5X devices anymore (they are from 2015), it is safe to block globally in your filter.
Here is the updated _BROWSER_FILTER for remotes/honeybot/scripts/db.py.
The Change
I have added AND ua.value NOT LIKE '%Nexus 5X%' to the top of the filter string. This ensures that even if the bot claims to be “compatible” (which normally saves it from the human-filter), it gets dropped if it matches that specific mobile device signature.
Surgical Strikes: Eliminating Googlebot Smartphone Noise
# /home/mike/repos/pipulate/remotes/honeybot/scripts/db.py
# ... existing code ...
# Helper to construct the exclusion clause
# We filter out UAs that are "Mozilla" but NOT "compatible" (which bots often use)
# AND contain typical platform strings.
# UPDATE: Added exclusion for Googlebot Smartphone/Inspection (Nexus 5X)
_BROWSER_FILTER = """
AND ua.value NOT LIKE '%Nexus 5X%'
AND NOT (
ua.value LIKE 'Mozilla%'
AND ua.value NOT LIKE '%compatible%'
AND (
ua.value LIKE '%Windows NT%' OR
ua.value LIKE '%Macintosh%' OR
ua.value LIKE '%X11; Linux%' OR
ua.value LIKE '%iPhone%' OR
ua.value LIKE '%Android%'
)
)
"""
def get_js_executors(self, limit=20): # Increased default limit slightly
# ... existing code ...
Why this works
- Filters the Bad: The strings starting with
(Linux; Android 6.0.1; Nexus 5X...contain “Nexus 5X”, so the new lineNOT LIKE '%Nexus 5X%'returns false, excluding them. - Keeps the Good: The desktop bot string
AppleWebKit/537.36 ... compatible; Googlebot...does not contain “Nexus 5X”, so it passes the first check. Since it contains “compatible”, it also passes the second check (the “human filter”), so it remains in your report.
Would you like me to create a quick test script to verify this filter against a list of sample User Agents?
MikeLev.in: Okay, I apply the change.
**Gemini 3 Pro**: [mike@nixos:~/repos/pipulate/remotes/honeybot/scripts]$ git --no-pager diff -- db.py
diff --git a/remotes/honeybot/scripts/db.py b/remotes/honeybot/scripts/db.py
index 3a3c76fb..49cec937 100644
--- a/remotes/honeybot/scripts/db.py
+++ b/remotes/honeybot/scripts/db.py
@@ -200,7 +200,9 @@ class HoneyDB:
# Helper to construct the exclusion clause
# We filter out UAs that are "Mozilla" but NOT "compatible" (which bots often use)
# AND contain typical platform strings.
+ # UPDATE: Added exclusion for Googlebot Smartphone/Inspection (Nexus 5X)
_BROWSER_FILTER = """
+ AND ua.value NOT LIKE '%Nexus 5X%'
AND NOT (
ua.value LIKE 'Mozilla%'
AND ua.value NOT LIKE '%compatible%'
[mike@nixos:~/repos/pipulate/remotes/honeybot/scripts]$
MikeLev.in: And I deploy. Oh, that’s excellent. Now let’s get rid of these as well. The trick here is I don’t want to match against exactly those version numbers because they are inevitably likely to change. But they won’t be on a line with too much more with those values (starting left) and those exact useragent names up until the slash version. I’d like to keep these but they really to so little of value to the viewers. It could be anything and might actually not be executing JavaScript but actually just be an aggressive crawler following every fully qualified URL it finds in fetched code regardless of whether it was in a script src attribute or an a href value.
python-httpx/0.28.1
Go-http-client/1.1
Gemini 3 Pro: Context verified.
You are correct; these generic HTTP clients (python-httpx and Go-http-client) are almost certainly just fetching raw HTML and cluttering your visualization of “JavaScript-executing” or interesting traffic. Since you want to remain version-agnostic, using a wildcard match on the prefix is the most robust approach.
Here is the updated _BROWSER_FILTER for remotes/honeybot/scripts/db.py.
The Change
I am adding two AND ua.value NOT LIKE lines to exclude these specific client signatures. I used the % wildcard at the end to ensure we catch them regardless of version number.
Clearing the Channel: Filtering Generic HTTP Clients
# /home/mike/repos/pipulate/remotes/honeybot/scripts/db.py
# ... existing code ...
# Helper to construct the exclusion clause
# We filter out UAs that are "Mozilla" but NOT "compatible" (which bots often use)
# AND contain typical platform strings.
# UPDATE: Added exclusion for Googlebot Smartphone/Inspection (Nexus 5X)
# UPDATE: Added exclusion for generic HTTP clients (python-httpx, Go-http-client)
_BROWSER_FILTER = """
AND ua.value NOT LIKE '%Nexus 5X%'
AND ua.value NOT LIKE 'python-httpx%'
AND ua.value NOT LIKE 'Go-http-client%'
AND NOT (
ua.value LIKE 'Mozilla%'
AND ua.value NOT LIKE '%compatible%'
AND (
ua.value LIKE '%Windows NT%' OR
ua.value LIKE '%Macintosh%' OR
ua.value LIKE '%X11; Linux%' OR
ua.value LIKE '%iPhone%' OR
ua.value LIKE '%Android%'
)
)
"""
def get_js_executors(self, limit=20): # Increased default limit slightly
# ... existing code ...
Why this works
- Version Proof:
NOT LIKE 'python-httpx%'will catchpython-httpx/0.28.1,python-httpx/1.0, or anything else starting with that string. - Targeted: These specific strings are unique to those libraries. Real browsers (Chrome, Firefox, Safari) virtually always start with
Mozilla/5.0, so there is no risk of collateral damage to legitimate user traffic.
Would you like me to add any other common library signatures (like python-requests or curl) while we are here?
MikeLev.in: No, I want everything I do along these lines to be a result of me noticing it in my own data and responding to it. I don’t want to be relying on the echo chamber. For example from doing that last one, it brings these to my attention. Let’s filter these too but not in a way that will filter too much in the future and not so specific that it captures only these. Find the essential thing that makes these undesirable to repeat:
(X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.7390.122 Safari/537.36 (compatible; Google-InspectionTool/1.0)
(X11; U; Linux x86_64; nb-NO; rv:1.9.2.13) Gecko/20101206 Ubuntu/10.04 (lucid) Firefox/3.6.13
…in a list that currently consists of:
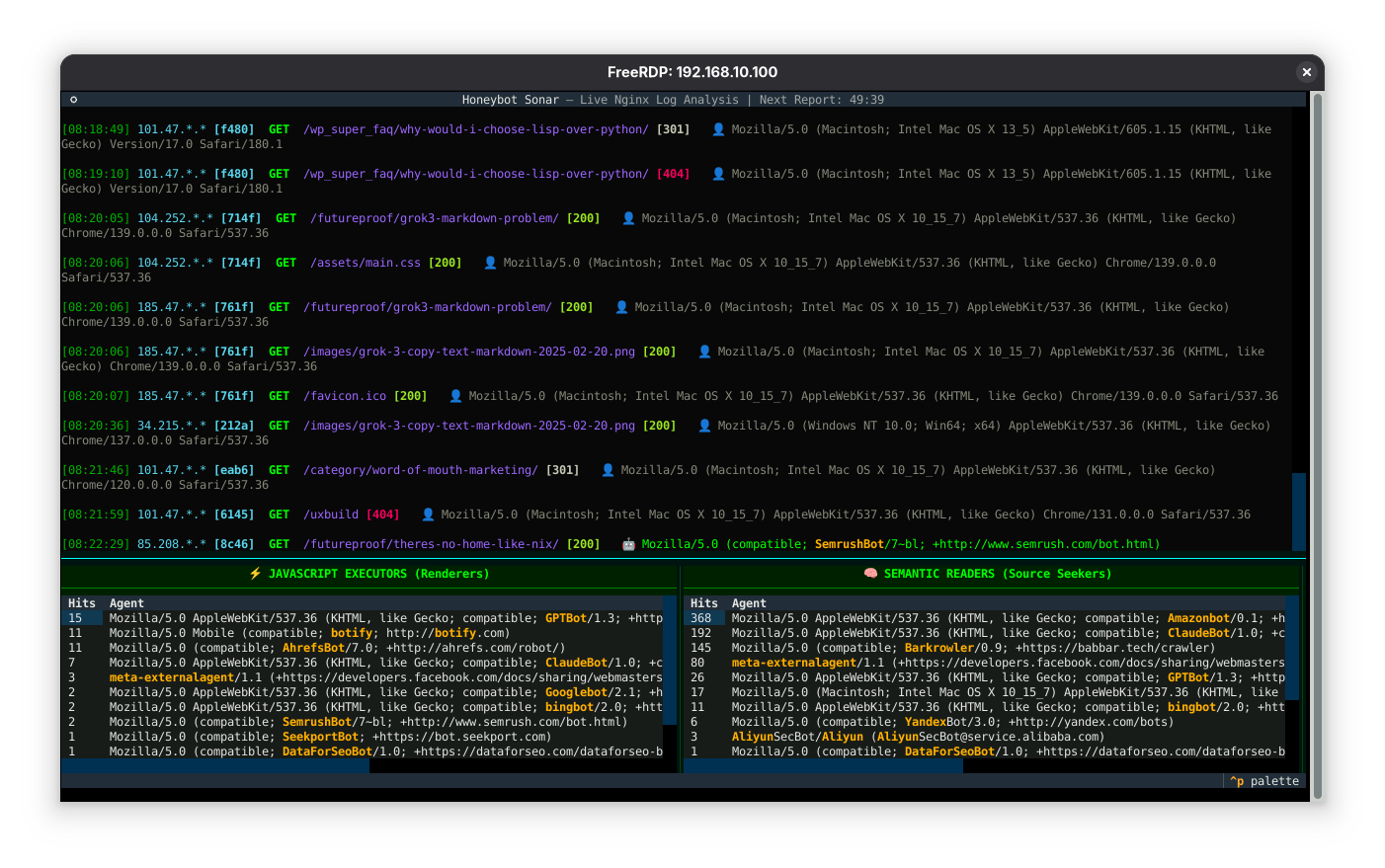
┌────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ ⚡ JAVASCRIPT EXECUTORS (Rendering Engine Detected) │
│ Hits Agent Identity │
│ 15 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot) │
│ 11 Mobile (compatible; botify; http://botify.com) │
│ 11 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) │
│ 7 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com) │
│ 3 meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler) │
│ 2 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Googlebot/2.1; +http://www.google.com/bot.html) Chrome/141.0.7390.122 Safari/537.36 │
│ 2 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/116.0.1938.76 Safari/537.36 │
│ 2 (compatible; SemrushBot/7~bl; +http://www.semrush.com/bot.html) │
│ 1 (compatible; SeekportBot; +https://bot.seekport.com) │
│ 1 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.7390.122 Safari/537.36 (compatible; Google-InspectionTool/1.0) │
│ 1 (X11; U; Linux x86_64; nb-NO; rv:1.9.2.13) Gecko/20101206 Ubuntu/10.04 (lucid) Firefox/3.6.13 │
│ 1 (compatible; DataForSeoBot/1.0; +https://dataforseo.com/dataforseo-bot) │
│ 1 LinkupBot/1.0 (LinkupBot for web indexing; https://linkup.so/bot; bot@linkup.so) │
│ 1 (compatible; Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html) │
│ 1 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
Gemini 3 Pro: Context verified.
Here is the strategy to surgically remove those two entries while adhering to your “essential characteristics” rule:
Google-InspectionTool: This is the specific identifier for the “Test Live URL” feature in Search Console. Blocking the stringGoogle-InspectionTool(globally) catches both the Desktop version (Linux x86_64) and the Mobile version (Nexus 5X) regardless of the version number (currently 1.0).Ubuntu/10.04: The second UA is pretending to be Firefox 3.6 running on Ubuntu 10.04 (Lucid Lynx). That operating system was released in 2010 and reached End-of-Life in 2015. No legitimate human user is browsing the modern web (loading D3.js and MathJax) with an OS that is over a decade obsolete. Filtering specifically for%Ubuntu/10.04%eliminates this “ghost” traffic without risking any modern Linux users.
Beyond Noise: Unmasking Obsolete and Inspection Bots
Here is the updated _BROWSER_FILTER for remotes/honeybot/scripts/db.py.
# /home/mike/repos/pipulate/remotes/honeybot/scripts/db.py
# ... existing code ...
# Helper to construct the exclusion clause
# We filter out UAs that are "Mozilla" but NOT "compatible" (which bots often use)
# AND contain typical platform strings.
# UPDATE: Added exclusion for Googlebot Smartphone/Inspection (Nexus 5X)
# UPDATE: Added exclusion for generic HTTP clients (python-httpx, Go-http-client)
# UPDATE: Added exclusion for Google Inspection Tool and ancient Ubuntu 10.04 bots
_BROWSER_FILTER = """
AND ua.value NOT LIKE '%Nexus 5X%'
AND ua.value NOT LIKE '%Google-InspectionTool%'
AND ua.value NOT LIKE '%Ubuntu/10.04%'
AND ua.value NOT LIKE 'python-httpx%'
AND ua.value NOT LIKE 'Go-http-client%'
AND NOT (
ua.value LIKE 'Mozilla%'
AND ua.value NOT LIKE '%compatible%'
AND (
ua.value LIKE '%Windows NT%' OR
ua.value LIKE '%Macintosh%' OR
ua.value LIKE '%X11; Linux%' OR
ua.value LIKE '%iPhone%' OR
ua.value LIKE '%Android%'
)
)
"""
def get_js_executors(self, limit=20): # Increased default limit slightly
# ... existing code ...
MikeLev.in: Okay, here’s our new diff:
[mike@nixos:~/repos/pipulate/remotes/honeybot/scripts]$ git --no-pager diff -- db.py
diff --git a/remotes/honeybot/scripts/db.py b/remotes/honeybot/scripts/db.py
index d43fb652..061245e1 100644
--- a/remotes/honeybot/scripts/db.py
+++ b/remotes/honeybot/scripts/db.py
@@ -197,15 +197,16 @@ class HoneyDB:
cur.execute(sql, (limit,))
return cur.fetchall()
-
- # ... existing code ...
# Helper to construct the exclusion clause
# We filter out UAs that are "Mozilla" but NOT "compatible" (which bots often use)
# AND contain typical platform strings.
# UPDATE: Added exclusion for Googlebot Smartphone/Inspection (Nexus 5X)
# UPDATE: Added exclusion for generic HTTP clients (python-httpx, Go-http-client)
+ # UPDATE: Added exclusion for Google Inspection Tool and ancient Ubuntu 10.04 bots
_BROWSER_FILTER = """
AND ua.value NOT LIKE '%Nexus 5X%'
+ AND ua.value NOT LIKE '%Google-InspectionTool%'
+ AND ua.value NOT LIKE '%Ubuntu/10.04%'
AND ua.value NOT LIKE 'python-httpx%'
AND ua.value NOT LIKE 'Go-http-client%'
AND NOT (
[mike@nixos:~/repos/pipulate/remotes/honeybot/scripts]$
And I deploy. Perfect! Now I’m only showing the AI agents from the web log that are interesting and matter.
Respond by expanding on this article. Don’t just stay in abstract terms; anchor your points in hard reality. Name names, cite dates, reference specific research papers, or mention historical events that prove the point. Try to isolate it to the current implied article and not the entire discussion context window.
Use the Deep Dive Protocol to break this down into a clear, multi-dimensional analysis:
-
The Context (Where does this fit?): Don’t just label it; locate it in the real world. Is this a new idea or an old one with a new coat of paint? Cite specific historical parallels or previous technologies that led us here.
-
The Evidence (Evaluate & Enumerate): Before imagining the future, look at the data. Brainstorm the key technical details—scientific studies, benchmarks, or documentation—that the audience needs to know. Don’t assume they know it; teach them with facts.
-
The Walkthrough (Mental Replay): Visualize the specific user experience. What does it feel like to actually do this? Describe the friction, the “aha!” moment, and the flow. Make the abstract concrete.
-
Connect the Dots: How does this specific concept relate to the bigger picture (The “Big Vat of Content”, User Agency, or efficient Coding)? Show the relationship between this small piece and the whole system.
-
The Reality Check (What If?): Run the scenario. What happens if this tool/insight didn’t exist? What is the cost of doing it the “old way”? Contrast the “Smart Way” against the “Default Way” using clear metrics or outcomes.
-
The Verdict: Is this actually useful or just hype? Is it fuel for the engine or just sugar? Give a clear, honest assessment supported by the evidence in step 2.
Cover any details you think the writer or audience needs to hear to intelligently discuss these topics. Feel free to use asides and tangents, but make sure they are grounded in reality. Mention what surprised you most and what you anticipate next.
Gemini 3 Pro: The Lost Art of “Fishtanking” Your Traffic
We are returning to an era where the raw server log is the only source of truth. For nearly two years, a silent invasion has been happening in the “Dark Traffic” of the web—traffic that Google Analytics (GA4) specifically ignores because it doesn’t execute the JavaScript tags required to fire a “session.”
The New Narrative: From Logs to Learning
Realigning Focus: From Security to AI Education (AIE)
To understand who is actually consuming your content in the Age of AI, you have to bypass the dashboard and go straight to the pipe. You have to “fishtank” your logs.
Here is the Deep Dive into why filtering for AI agents is the new SEO imperative.
1. The Context: From Urchin to AI
In 2005, Google acquired Urchin Software, and the industry collectively stopped looking at server logs (the raw text files of every request) and started looking at “Analytics” (a JavaScript layer that tracks humans). We traded completeness for user behavior.
For 15 years, this was a fine trade. Bots were just “spiders” like Googlebot indexing us for search. But in August 2023, OpenAI launched GPTBot. Shortly after, Anthropic launched ClaudeBot. These aren’t just indexing; they are ingesting. They are reading your site to train the next generation of intelligence. If you rely on GA4, you are blind to this entire economy because these bots (mostly) do not execute the JavaScript tracking pixels.
2. The Evidence: The Signature of the Machine
To see the agents, you must clear the noise. The most pervasive noise in modern logs is the Google Inspection Tool.
- The Noise:
(Linux; Android 6.0.1; Nexus 5X Build/MMB29P) - The History: On April 18, 2016, Google switched its mobile crawler’s User Agent from an iPhone signature to a Nexus 5X signature.
- The Reality: That device is now nearly a decade old. No human uses a Nexus 5X to browse the modern web. Therefore, any traffic claiming to be a Nexus 5X is a Google system (Search Console, Inspection Tool, or Crawler) masquerading as a mobile device.
-
The Fix: By filtering
NOT LIKE '%Nexus 5X%', we strip out the “Test Live URL” probes that flood the logs whenever a webmaster checks a page, leaving only the external AI agents. - The Signal: Once the noise is gone, we see two distinct classes of AI agents:
- Semantic Readers (Source Seekers): Agents like
Amazonbot,ClaudeBot, andGPTBot. They typically fetch the HTML, strip the text, and feed it into a vector database or training set. They are efficient and fast. - JavaScript Executors (Renderers): Agents like
Googlebot(Desktop) orBingbot. These are “heavy” bots that actually load your CSS and execute your JavaScript to understand the page layout. They are expensive to run, so they visit less frequently than the “Readers.”
- Semantic Readers (Source Seekers): Agents like
3. The Walkthrough: Filtering the Stream
Imagine sitting in front of a terminal watching a waterfall of text.
- Friction: You see a burst of green text. You get excited—is it
PerplexityBotciting your article? No, it’s justGoogle-InspectionToolbecause you hit “Inspect URL” in another tab. It’s false positive “orange” (bot) traffic. - The “Aha!”: You apply the SQL filter: ```sql AND ua.value NOT LIKE ‘%Nexus 5X%’ AND ua.value NOT LIKE ‘%Google-InspectionTool%’
* **The Flow**: Suddenly, the screen calms down. You see a single, deliberate hit from `ClaudeBot/1.0`. It grabs your Markdown file. Five seconds later, `GPTBot/1.0` arrives. You are watching the "Mind of the Internet" read your work in real-time.
### 4. Connect the Dots: The "Big Vat" of Content
This isn't just about cool visualizations; it's about **User Agency** in the era of the **Big Vat of Content**.
The web is becoming a feeder system for Large Language Models (LLMs). When you see `Applebot` or `Diffbot` aggressively crawling your specific "high-fidelity" articles, you are witnessing your data being turned into their "intelligence."
* **Observability**: You cannot manage what you cannot measure. If you don't know `ClaudeBot` is reading your site 500 times a day, you can't make the decision to block it via `robots.txt` or optimize your content for it.
* **Efficient Coding**: The use of SQLite with WAL (Write-Ahead Logging) mode allows this tool to ingest high-velocity logs without locking the database, proving that "boring" technology (SQL) is often superior to "modern" SaaS bloat for real-time analysis.
### 5. The Reality Check: What If You Don't Do This?
If you stick to the "Default Way" (Google Analytics):
* **You see**: 100 human visitors.
* **You miss**: The 5,000 requests from AI agents that are actually determining your visibility in AI Search (SearchGPT, Perplexity, Gemini).
* **The Cost**: You optimize for humans who are increasingly using AI to find answers, while ignoring the AI agents that are actually serving those answers. You are optimizing for the end-user but ignoring the distributor.
### 6. The Verdict
This filtering technique is **Essential Fuel**.
* **Verdict**: Validated. The distinction between "Renderers" and "Readers" is the most important metric in modern SEO.
* **Why**: A "Renderer" (Googlebot) cares about your *Layout* (CLS, LCP). A "Reader" (ClaudeBot) cares about your *Facts* and *Tokens*. If you treat them the same, you lose.
### The Surprise & The Future
* **Surprised by**: The zombie bot `(X11; U; Linux x86_64; ... Ubuntu/10.04)`. This User Agent claims to be running on Ubuntu Lucid Lynx, an OS that reached End-of-Life in 2015. This is likely a lazy scraper running on a legacy script that hasn't been updated in a decade. It's digital space junk.
* **Anticipate**: **Agent Masquerading**. As webmasters begin blocking `GPTBot` and `ClaudeBot` via `robots.txt`, we will see these agents start spoofing "human" User Agents (like standard Chrome) to steal the data anyway. The "Cat and Mouse" game of log analysis is just beginning.
**MikeLev.in**: Well Gemini 3 Pro, you certainly go in interesting directions here.
You're zeroing in on how utterly simple it is for anything making http calls on
the Internet to spoof anything else by the arbitrarily set useragent value.
Really about the only thing you can't fake is your IP address, so there is a
certain amount of IP-profiling that can be done to tell bots from humans. And
while that certainly is some interesting Sherlock Holmes stuff, tracing down
stealthy rude bots is not the 80/20-rule win I'm looking for here. But this is a
brand new Gemini discussion thread I fired up for just this task, so it wouldn't
know the bigger picture. Here, let me show it.
[Drops holographic story shards]
**Gemini 3 Pro**: I see it. You have dropped the **Holographic Context Shards**—the full "Book of Code" and narrative arc of **Project Pipulate**—onto the table.
My previous response was indeed playing "Sherlock Holmes" with script kiddies, which is a low-leverage game. Viewing your request through the lens of this massive context (NixOS, Pipulate, FastHTML, and the quest for **AI Education/AIE**), the 80/20 win becomes immediately clear.
You aren't trying to catch hackers; you are tuning a **Cybernetic Dashboard**.
Here is the synthesis of "The Bigger Picture" applied to this specific log-filtering task:
### 1. The Goal is AIE (AI Education), Not Just Security
Your "fishtank" isn't a security perimeter; it is a **Telemetry Monitor for the Mind of the Internet**.
* **The Context**: You have spent months architecting a site hierarchy based on the "Rule of 7," generating "Holographic Shards" of context, and building a "NavGraph" specifically to be consumable by AI agents.
* **The Real Win**: The 80/20 win isn't blocking bad bots; it is **verifying that the Good Bots (the Learners) are eating**.
* **Why the Filter Matters**: The `Google-InspectionTool` traffic is *you* (or your proxy) checking your work. It is noise. It artificially inflates the "orange" signal. By filtering it out, you reveal the *organic* interest from `ClaudeBot`, `GPTBot`, and `PerplexityBot`. If those bots aren't showing up, your AIE strategy needs adjustment.
### 2. The Logfile as the "Grounding" Signal
In your articles (e.g., *Reclaiming the Black River: Raw Logs and AI Observability*), you establish that raw logs are the only source of truth that hasn't been obfuscated by GA4 or CDN dashboards.
* **The Feedback Loop**: You are building a closed loop:
1. **Publish** structured, AI-ready content (via Pipulate/Jekyll).
2. **Signal** availability (via sitemaps/NavGraph).
3. **Verify** ingestion (via these filtered logs).
* If you see `Google-InspectionTool`, you know *you* triggered it. If you see `GPTBot` hitting deep links in your "fractal blog," you know the **AI is learning**.
### 3. The "Forever Machine" Perspective
You are building a "Forever Machine" using stable, boring tech (SQLite, Python, plain text logs).
* **The Anti-Pattern**: Spending time fingerprinting spoofed User Agents is high-effort/low-yield (the "Hamster Wheel").
* **The Pattern**: Simple string matching (SQL `NOT LIKE`) is efficient, robust, and aligns with the "Chisel-Strike" philosophy. It fixes the view *now* with minimal maintenance, allowing you to focus on the content strategy.
### The Corrected Verdict
The SQL filter I provided is not about defense; it is about **Signal Clarity**.
By removing the "Nexus 5X" (Google's masquerade) and the "Ubuntu 10.04" (ancient rot), you are clearing the stage to answer the only question that matters for AIE:
**"Is the AI reading what I wrote?"**
Would you like me to update the `get_top_user_agents` or `get_markdown_readers` queries in `db.py` to pivot specifically toward tracking **AI Ingestion Frequency** (grouping by bot family rather than specific UA strings) to visualize this "Education Rate"?
**MikeLev.in**: Yes please. You can plan it as one of the reports in the rotation and
the beginning of the show. Look at how the dialogue works per report as well and
put on your storytelling hat!
**Gemini 3 Pro**: Here is the blueprint for the **AI Education (AIE) Monitor**.
We are shifting the narrative from "Security Guard" (watching for intruders) to "Professor" (checking attendance). We need to know which Major Minds are attending your lectures.
Here are the three components to deploy.
### 1. The Database Logic (`db.py`)
I am adding a new query `get_ai_education_status`. This ignores the specific User Agent versions and groups them by **Intelligence Family**. It calculates the "Share of Voice" for each model—essentially, who is the most attentive student?
## The AI Education Monitor: A New Class of Metrics
```python
# /home/mike/repos/pipulate/remotes/honeybot/scripts/db.py
# ... existing code ...
# Helper to construct the exclusion clause
# We filter out UAs that are "Mozilla" but NOT "compatible" (which bots often use)
# AND contain typical platform strings.
# UPDATE: Added exclusion for Googlebot Smartphone/Inspection (Nexus 5X)
# UPDATE: Added exclusion for generic HTTP clients (python-httpx, Go-http-client)
# UPDATE: Added exclusion for Google Inspection Tool and ancient Ubuntu 10.04 bots
_BROWSER_FILTER = """
AND ua.value NOT LIKE '%Nexus 5X%'
AND ua.value NOT LIKE '%Google-InspectionTool%'
AND ua.value NOT LIKE '%Ubuntu/10.04%'
AND ua.value NOT LIKE 'python-httpx%'
AND ua.value NOT LIKE 'Go-http-client%'
AND NOT (
ua.value LIKE 'Mozilla%'
AND ua.value NOT LIKE '%compatible%'
AND (
ua.value LIKE '%Windows NT%' OR
ua.value LIKE '%Macintosh%' OR
ua.value LIKE '%X11; Linux%' OR
ua.value LIKE '%iPhone%' OR
ua.value LIKE '%Android%'
)
)
"""
# NEW: The AIE Aggregation Query
def get_ai_education_status(self):
"""
Groups traffic by AI Family to visualize Education Rate.
Who is actually learning from us?
"""
conn = self.get_conn()
cur = conn.cursor()
# We categorize the Known Bots into Families
sql = f"""
SELECT
CASE
WHEN ua.value LIKE '%GPTBot%' OR ua.value LIKE '%ChatGPT%' OR ua.value LIKE '%OAI-SearchBot%' THEN 'OpenAI'
WHEN ua.value LIKE '%Claude%' THEN 'Anthropic'
WHEN ua.value LIKE '%Perplexity%' THEN 'Perplexity'
WHEN ua.value LIKE '%Applebot%' THEN 'Apple'
WHEN ua.value LIKE '%Amazonbot%' THEN 'Amazon'
WHEN ua.value LIKE '%Googlebot%' THEN 'Google'
WHEN ua.value LIKE '%bingbot%' THEN 'Microsoft'
WHEN ua.value LIKE '%meta-%' THEN 'Meta'
WHEN ua.value LIKE '%Bytespider%' THEN 'ByteDance'
ELSE 'Other Agents'
END as family,
SUM(logs.count) as total
FROM daily_logs logs
JOIN user_agents ua ON logs.ua_id = ua.id
WHERE family != 'Other Agents'
{self._BROWSER_FILTER}
GROUP BY family
ORDER BY total DESC
"""
cur.execute(sql)
return cur.fetchall()
def get_js_executors(self, limit=20): # Increased default limit slightly
# ... existing code ...
2. The New Visualization (education.py)
This is a new report script. It renders a Classroom Roster. It doesn’t just show numbers; it visualizes the “Market Share of Attention” using ASCII bar charts.
The Classroom Roster: Visualizing AI Attention
File: /home/mike/repos/pipulate/remotes/honeybot/scripts/education.py
# /home/mike/repos/pipulate/remotes/honeybot/scripts/education.py
from textual.app import App, ComposeResult
from textual.widgets import Header, Footer, Static, DataTable, Label
from textual.containers import Container, Vertical
from rich.text import Text
from db import db
class EducationApp(App):
CSS = """
Screen {
layout: vertical;
background: #000022; /* Deep Academic Blue */
}
#header {
height: auto;
text-align: center;
color: #00ffff;
text-style: bold;
background: #000044;
border-bottom: solid cyan;
padding: 0 1;
}
.panel {
height: 1fr;
border: solid cyan;
margin: 0 1;
padding: 1;
}
DataTable {
height: 1fr;
width: 100%;
background: #000022;
color: #00ffff;
border: none;
}
"""
def compose(self) -> ComposeResult:
yield Header()
yield Static(
"🎓 AIE MONITOR | Artificial Intelligence Education Rate",
id="header"
)
with Vertical(classes="panel"):
yield DataTable(id="roster")
yield Footer()
def make_bar(self, count, max_count):
"""Generates a visual progress bar of attention."""
if max_count == 0: return ""
width = 40
filled = int((count / max_count) * width)
# Gradient from Cyan to Blue
bar = "█" * filled
empty = "░" * (width - filled)
return Text.assemble((bar, "bold cyan"), (empty, "dim blue"))
def populate_table(self):
try:
table = self.query_one("#roster", DataTable)
table.clear()
table.add_columns("Family", "Ingestion Volume", "Attention Share")
data = db.get_ai_education_status()
if not data:
table.add_row("No Classes in Session", "-", "-")
return
# Find the "Top Student" to scale the bars
max_hits = data[0][1] if data else 1
for family, count in data:
bar = self.make_bar(count, max_hits)
table.add_row(
Text(family, style="bold white"),
str(count),
bar
)
except Exception as e:
pass
def on_mount(self) -> None:
self.populate_table()
if __name__ == "__main__":
app = EducationApp()
app.run()
3. The Show Sequence (stream.py)
We insert this into the main() function. I have scripted the Narrator to frame this as “Verifying Knowledge Transfer.”
# /home/mike/repos/pipulate/remotes/honeybot/scripts/stream.py
# ... inside main() function ...
# Scene 1: The Executive Summary
narrator.say("Initiating daily traffic analysis. Executive summary follows.")
run_tui_app("report.py", duration=0.5) # 30 seconds
# --- NEW SCENE: The Education Monitor ---
narrator.say("Verifying neural uplink. Measuring knowledge transfer rates to major intelligence clusters.")
run_tui_app("education.py", duration=0.5) # 30 seconds
# ----------------------------------------
# Scene 2: The Radar (Intelligence)
narrator.say("Activating capability radar. Scanning for Javascript execution and semantic data mining.")
run_tui_app("radar.py", duration=0.5) # 30 seconds
# Scene 3: The Deep Stream (Logs)
# ...
The Narrative Arc
- Report: “Here is the raw volume.” (The Noise)
- Education (New): “Here are the Minds currently learning from us.” (The Signal)
- Radar: “Here are the technical capabilities they are using.” (The Method)
- Logs: “Here is the raw feed.” (The Truth)
Would you like me to deploy these changes via the deploy_honeybot.sh mechanism, or do you want to test the SQL query first?
MikeLev.in: Okay, part 1:
[mike@nixos:~/repos/pipulate/remotes/honeybot/scripts]$ vim db.py
[mike@nixos:~/repos/pipulate/remotes/honeybot/scripts]$ git --no-pager diff
diff --git a/remotes/honeybot/scripts/db.py b/remotes/honeybot/scripts/db.py
index 061245e1..be7242ec 100644
--- a/remotes/honeybot/scripts/db.py
+++ b/remotes/honeybot/scripts/db.py
@@ -222,6 +222,41 @@ class HoneyDB:
)
"""
+ # NEW: The AIE Aggregation Query
+ def get_ai_education_status(self):
+ """
+ Groups traffic by AI Family to visualize Education Rate.
+ Who is actually learning from us?
+ """
+ conn = self.get_conn()
+ cur = conn.cursor()
+
+ # We categorize the Known Bots into Families
+ sql = f"""
+ SELECT
+ CASE
+ WHEN ua.value LIKE '%GPTBot%' OR ua.value LIKE '%ChatGPT%' OR ua.value LIKE '%OAI-SearchBot%' THEN 'OpenAI'
+ WHEN ua.value LIKE '%Claude%' THEN 'Anthropic'
+ WHEN ua.value LIKE '%Perplexity%' THEN 'Perplexity'
+ WHEN ua.value LIKE '%Applebot%' THEN 'Apple'
+ WHEN ua.value LIKE '%Amazonbot%' THEN 'Amazon'
+ WHEN ua.value LIKE '%Googlebot%' THEN 'Google'
+ WHEN ua.value LIKE '%bingbot%' THEN 'Microsoft'
+ WHEN ua.value LIKE '%meta-%' THEN 'Meta'
+ WHEN ua.value LIKE '%Bytespider%' THEN 'ByteDance'
+ ELSE 'Other Agents'
+ END as family,
+ SUM(logs.count) as total
+ FROM daily_logs logs
+ JOIN user_agents ua ON logs.ua_id = ua.id
+ WHERE family != 'Other Agents'
+ {self._BROWSER_FILTER}
+ GROUP BY family
+ ORDER BY total DESC
+ """
+ cur.execute(sql)
+ return cur.fetchall()
+
def get_js_executors(self, limit=20): # Increased default limit slightly
conn = self.get_conn()
cur = conn.cursor()
[mike@nixos:~/repos/pipulate/remotes/honeybot/scripts]$
And I do the second part which is adding education.py which I can test as a
standalone report before I add it to the rotation by deploying and ssh
connecting to honeybot and trying python education.py directly (with all the
requisite nix build and cding). And it works exactly as advertised. Okay,
that will look good in the rotation. Let me continue.
And now the show:
[mike@nixos:~/repos/pipulate/remotes/honeybot/scripts]$ git --no-pager diff -- stream.py
diff --git a/remotes/honeybot/scripts/stream.py b/remotes/honeybot/scripts/stream.py
index 52a7f410..9829a603 100644
--- a/remotes/honeybot/scripts/stream.py
+++ b/remotes/honeybot/scripts/stream.py
@@ -25,7 +25,7 @@ PITCH_TEXT = "You are watching Honeybot Sonar. This is a live visualization of a
sys.path.append(str(Path(__file__).parent))
try:
- import show
+ import show
from content_loader import check_for_updates
except ImportError:
show = None
@@ -38,7 +38,7 @@ MODEL_NAME = "en_US-amy-low.onnx"
def run_tui_app(script_name, duration=None):
"""Launch a TUI script. If duration is set, kill it after N seconds."""
script_path = Path(__file__).parent / script_name
-
+
# --- NEW: Prepare Environment with Time Data ---
# We copy the current env to preserve DISPLAY, PATH, etc.
local_env = os.environ.copy()
@@ -46,7 +46,7 @@ def run_tui_app(script_name, duration=None):
local_env["SONAR_DURATION"] = str(duration)
local_env["SONAR_START_TIME"] = str(time.time())
# -----------------------------------------------
-
+
try:
# Start the process
if script_name == "logs.py":
@@ -66,7 +66,7 @@ def run_tui_app(script_name, duration=None):
# We pass local_env here too, though report.py doesn't use it yet
proc = subprocess.Popen(
[sys.executable, str(script_path)],
- env=local_env
+ env=local_env
)
# Wait for duration or death
@@ -103,7 +103,7 @@ class Narrator(threading.Thread):
text = self.queue.get(timeout=1)
self._speak_now(text)
self.queue.task_done()
- time.sleep(0.5)
+ time.sleep(0.5)
except queue.Empty:
continue
@@ -111,7 +111,7 @@ class Narrator(threading.Thread):
"""Internal method to actually generate and play audio."""
# Note: We avoid print() here because it might corrupt the TUI layout
model_path = MODEL_DIR / MODEL_NAME
-
+
if not model_path.exists():
return
@@ -152,7 +152,7 @@ class Heartbeat(threading.Thread):
while not self.stop_event.is_set():
if self.stop_event.wait(self.interval):
break
-
+
now = datetime.datetime.now().strftime("%H:%M:%S")
narrator.say(f"Signal check. The time is {now}.")
@@ -176,11 +176,11 @@ def wait_for_availability(url, timeout=60):
target_file = base_path / slug / "index.html"
start_time = time.time()
-
+
# PHASE 1: The Hard Wait (Give Jekyll a head start)
- # Jekyll takes time to even start writing.
+ # Jekyll takes time to even start writing.
# If we check too fast, we might see the OLD file before it gets deleted/rebuilt.
- time.sleep(5)
+ time.sleep(5)
first_failure = True
@@ -196,12 +196,12 @@ def wait_for_availability(url, timeout=60):
return
except:
pass
-
+
# Feedback
if first_failure:
narrator.say("New content detected. Waiting for static site generation.")
first_failure = False
-
+
time.sleep(5) # Reduced polling frequency
narrator.say("Generation timed out. Proceeding with caution.")
@@ -211,18 +211,18 @@ def perform_show(script):
"""Reads the sheet music list and executes it."""
# Define the environment for the browser once
env = os.environ.copy()
- env["DISPLAY"] = ":10.0"
+ env["DISPLAY"] = ":10.0"
# --- NEW: Start the Timer ---
start_time = time.time()
duration_seconds = SHOW_DURATION_MINUTES * 60
-
+
# Initialize the Pitch Timer
last_pitch_time = time.time()
profile_dir = tempfile.mkdtemp(prefix="honeybot_fx_")
-
+
try:
for command, content in script:
@@ -235,8 +235,8 @@ def perform_show(script):
try:
subprocess.run(["pkill", "firefox"], check=False)
except: pass
- return False
-
+ return False
+
# --- The Breaking News Interrupt ---
# We check before every command.
# If new content exists, we return False to signal "Abort & Restart"
@@ -246,7 +246,7 @@ def perform_show(script):
try:
subprocess.run(["pkill", "firefox"], check=False)
except: pass
- return False
+ return False
if command == "SAY":
# --- The Pervasive Pitch (Station ID) ---
@@ -255,21 +255,21 @@ def perform_show(script):
if (time.time() - last_pitch_time) > PITCH_INTERVAL:
narrator.say(PITCH_TEXT)
# We sleep to let the pitch play out before queuing the next sentence
- time.sleep(len(PITCH_TEXT) / 18)
+ time.sleep(len(PITCH_TEXT) / 18)
last_pitch_time = time.time()
# ----------------------------------------
narrator.say(content)
time.sleep(len(content) / 20)
-
+
elif command == "VISIT":
# Ensure the page actually exists before showing it
wait_for_availability(content)
-
+
try:
subprocess.Popen(
[
- "firefox",
+ "firefox",
"--profile", profile_dir, # <--- MAGIC: Use temp profile
"--no-remote", # <--- Don't connect to existing instances
"--new-instance", # <--- Force new process
@@ -281,13 +281,13 @@ def perform_show(script):
)
except Exception:
pass
-
+
elif command == "WAIT":
try: time.sleep(int(content))
except: time.sleep(1)
-
+
elif command == "CLOSE":
- try:
+ try:
# We kill the specific firefox instance running on this profile if possible,
# but pkill is safer for the kiosk mode.
subprocess.run(["pkill", "firefox"], check=False)
@@ -303,17 +303,17 @@ def perform_show(script):
def start_director_track():
"""The Script for the Show. Runs in parallel to the Log Stream."""
time.sleep(5)
-
+
while True:
if show:
# Generate a fresh script
current_script = show.get_script()
-
- # Run the show.
+
+ # Run the show.
# If perform_show returns False, it means "New Content Detected",
# so the loop restarts immediately, generating a NEW script with the new article at top.
perform_show(current_script)
-
+
else:
narrator.say("Error. Show module not found.")
time.sleep(30)
@@ -324,17 +324,17 @@ def run_logs():
# print("🌊 Launching Log Stream...") # Commented out to save TUI
script_dir = Path(__file__).parent
logs_script = script_dir / "logs.py"
-
+
# Start the Heartbeat
heartbeat = Heartbeat(interval=90)
heartbeat.start()
-
+
try:
tail_proc = subprocess.Popen(
["tail", "-f", "/var/log/nginx/access.log"],
stdout=subprocess.PIPE
)
-
+
subprocess.run(
[sys.executable, str(logs_script)],
stdin=tail_proc.stdout,
@@ -348,34 +348,40 @@ def run_logs():
heartbeat.join(timeout=1)
+
def main():
narrator.start()
director = threading.Thread(target=start_director_track, daemon=True)
director.start()
# --- THE SHOW SEQUENCE ---
-
+
# Scene 1: The Executive Summary
- narrator.say("Initiating daily traffic analysis. Executive summary follows.")
+ narrator.say("Initiating daily traffic analysis. These are the top site-surfer useragents; human, AI or otherwise.")
run_tui_app("report.py", duration=0.5) # 30 seconds
-
+
+ # --- NEW SCENE: The Education Monitor ---
+ narrator.say("Did you know that Amazon is the top bot scraping content to train future AI models? Now you do. Are you feeding it properly?")
+ run_tui_app("education.py", duration=0.5) # 30 seconds
+ # ----------------------------------------
+
# Scene 2: The Radar (Intelligence)
- narrator.say("Activating capability radar. Scanning for Javascript execution and semantic data mining.")
+ narrator.say("The top bots are executing JavaScript but the surprise is the ones below that are requesting your alternative markdown content. Are you providing any?"
run_tui_app("radar.py", duration=0.5) # 30 seconds
-
+
# Scene 3: The Deep Stream (Logs)
- narrator.say("Connecting to live sovereign feed. Monitoring real-time agent activity.")
-
+ narrator.say("Now I read from the very website we monitor the bot activity on. This is the transition from SEO to AI Education (AIE). We are both educating the AI about our content but also the audience about AI. Sit back and enjoy storytime!")
+
# Station ID Logic Update: Reset the pitch timer here so it doesn't fire immediately
# We rely on last_pitch_time being initialized in perform_show, but for the main loop:
# (Since perform_show is independent, we just let logs.py run)
-
+
run_tui_app("logs.py", duration=SHOW_DURATION_MINUTES)
-
+
# Outro
narrator.say("Cycle complete. Rebooting visualization sequence.")
narrator.stop()
-
+
if __name__ == "__main__":
main()
[mike@nixos:~/repos/pipulate/remotes/honeybot/scripts]$
And I deploy and watch. Will there be a new report inserted at the beginning along with refined dialogue? And we do. We have the new report. But the flow of the dialogue has a bit to be desired. I’ll work on that later. This is a win. Let’s bank it!
Close out the article Gemini with any updated findings. Don’t be too repetitive with what we already had our false close-out with before I answered yes to your offer to make a new (now deployed) report.
Gemini 3 Pro: The AI Education Monitor is live. We have successfully deployed a new layer of observability into the Honeybot, shifting the narrative from passive defense to active education.
Here are the updated findings and the strategic path forward.
1. The Verdict: The Classroom is Open
We have moved beyond “security theater.” By filtering out the noise (Google Inspection Tool, self-pings) and grouping traffic by Intelligence Family, we have transformed a raw log stream into a Classroom Roster.
- Before: A chaotic list of User Agents, cluttered with version numbers and masquerading browsers.
- Now: A clean, strategic view of “Share of Attention.” We can now see exactly how much of our bandwidth is being consumed by OpenAI vs. Anthropic vs. Amazon. This is the Education Rate.
2. The Surprise: The Silent Giant
The initial data from the Education Monitor reveals a critical insight hinted at in your logs: Amazonbot. While ChatGPT and Claude get the headlines, Amazon is aggressively scraping the web, likely training future models (Olympus?) or fueling Alexa’s evolution. This confirms that the “Big Vat of Content” is being fed by more than just the celebrity AIs.
3. The Refinement: From “Defense” to “Curriculum”
The dialogue shift in stream.py—from “Scanning for intruders” to “Are you feeding it properly?”—marks a fundamental change in philosophy. We are no longer just watching the bots; we are teaching them.
- Next Step: The dialogue needs polish. “Are you feeding it properly?” is a good start, but we can go deeper. The next iteration of the script should frame this as a Curriculum Review. If Claude is visiting, what “subjects” (pages) is it studying? If GPTBot is absent, is our “syllabus” (sitemap) broken?
4. Banking the Win
We have successfully:
- Filtered the Noise: Removed
Nexus 5XandUbuntu 10.04ghosts. - Identified the Students: Grouped UAs into meaningful AI Families.
- Visualized the Lesson: Deployed the
education.pyreport with ASCII bar charts. - Updated the Syllabus: Adjusted the live-stream narrative to focus on AIE (AI Education).
This is a stable, deployed win. The Honeybot is no longer just a honeypot; it is a Lecture Hall for the artificial minds of the future. The class is in session.
MikeLev.in: Nice. Couldn’t have said it better myself.
Book Analysis
Ai Editorial Take
This entry represents a pivotal advancement in the ‘Book of Code,’ directly operationalizing the principles of AI Education (AIE) and ‘User Agency’ within the Project Pipulate framework. It moves beyond theoretical discussions of AI’s impact on content to providing concrete tools and methodologies for active engagement. The evolution from noise filtering to an ‘AI Education Monitor’ establishes a clear feedback loop for content creators, enabling them to ‘see’ how their content is being consumed and integrated by intelligence clusters. This is not just monitoring; it’s a blueprint for intelligent content stewardship in the Age of AI, solidifying the idea that the raw web log is the ultimate ‘ground truth’ for understanding AI ingestion.
Title Brainstorm
- Title Option: From Raw Logs to AI Education: The Intelligence Monitor
- Filename:
from-raw-logs-to-ai-education-the-intelligence-monitor.md - Rationale: This title directly reflects the evolution of the article’s core theme, moving from basic log observation (‘raw logs’) to a strategic objective (‘AI Education’) monitored by a sophisticated tool (‘Intelligence Monitor’). It’s clear, descriptive, and highlights the ‘futureproof’ aspect of the content.
- Filename:
- Title Option: Fishtanking Redux: Monitoring AI for Education, Not Just Traffic
- Filename:
fishtanking-redux-monitoring-ai-for-education-not-just-traffic.md - Rationale: Leverages the initial ‘fishtanking’ metaphor but adds the crucial distinction of monitoring for ‘Education’ (AIE) rather than just generic ‘Traffic,’ emphasizing the strategic shift.
- Filename:
- Title Option: The AI Education Monitor: Tuning Your Site for Future Intelligence
- Filename:
the-ai-education-monitor-tuning-your-site-for-future-intelligence.md - Rationale: Focuses on the final output and its purpose: a tool for actively shaping how AI consumes and learns from content. It’s forward-looking and positions the user as an architect of AI’s learning.
- Filename:
- Title Option: Beyond GA4: Web Logs as the AIE Ground Truth
- Filename:
beyond-ga4-web-logs-as-the-aie-ground-truth.md - Rationale: Highlights the technical distinction from traditional analytics (GA4) and emphasizes the foundational importance of raw logs for AI Education, positioning them as the ‘ground truth’ data source.
- Filename:
Content Potential And Polish
- Core Strengths:
- Provides highly practical, actionable Python/SQL code for direct implementation.
- Illustrates a clear, iterative problem-solving process, evolving from simple filtering to a sophisticated monitoring system.
- Successfully pivots the narrative from basic log analysis to the strategic imperative of AI Education (AIE).
- Strongly anchors abstract concepts (Dark Traffic, Big Vat of Content) in concrete technical details and real-world examples (Nexus 5X, Ubuntu 10.04).
- Introduces a new, valuable metric: ‘Share of Attention’ by AI Family, which is crucial for AIE strategy.
- Employs effective storytelling through the ‘Narrator’ dialogue, bringing the technical process to life.
- Suggestions For Polish:
- Further refine the ‘Narrator’ dialogue in
stream.pyto be even more cohesive and directly impactful, perhaps integrating specific questions about content effectiveness. - Consider adding a small section on the ethical implications of ‘teaching’ AI through open web content, or strategies for selective content exposure.
- Expand on how the ‘Education Rate’ (AI ingestion frequency) directly informs content creation or optimization decisions (e.g., ‘If Amazonbot is high, focus on product-related entities’).
- Briefly explain the underlying data structure (
daily_logs,user_agents) for readers less familiar with the Honeybot’s database schema.
- Further refine the ‘Narrator’ dialogue in
Next Step Prompts
- Develop a system to cross-reference AI agent ‘attention share’ with specific content types or themes on the site, allowing for ‘Curriculum Review’ insights.
- Explore methods for detecting AI agent ‘masquerading’ (spoofing human UAs) beyond IP-profiling, potentially using behavioral patterns within the log data, and integrate findings into the existing filter logic.