Google Search Console API Python Example: Trend Analysis
Technical Journal Entry Begins
Something’s up in my personal test-site’s Google Search Console (GSC) — and that something is impressions. Looking at a hockeystick curve like this makes you wonder what’s the story? There is a per-keyword / per-URL story here — an analysis every SEO should be able to do: identifying sudden movers & shakers using steep-slope linear regression. That’s sortable sparklines to you Excel wonks. I’ll try to walk you through it gently.
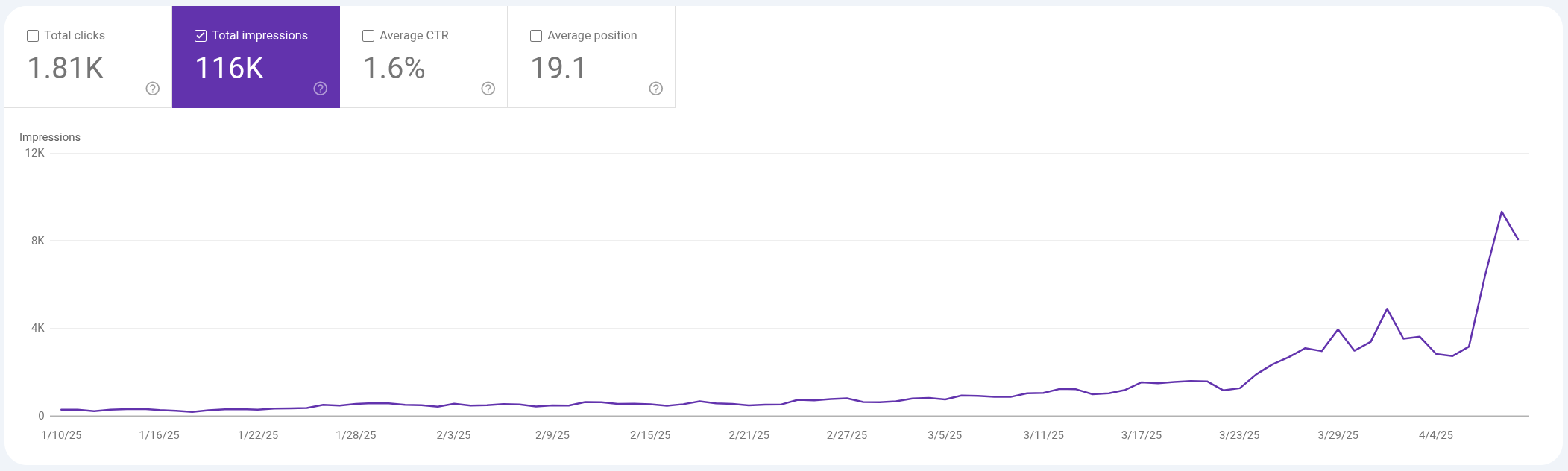
You Need More Granular Data Than GSC Lets You Download
How many times have you wanted to download more than 1000 pages or queries from
the GSC web user interface, and said “oh, you can do that with the API,” but
then never really done it? This is the page resource to make it as easy as
reasonably possible for you. And it’s worse than getting more than 1000. It’s
not having to switch between queries and pages tabs on the final download.
It’s having per-query/per-page in the same table.
Per Keyword Per URL
It’s a little tough to wrap your mind around at first. But every URL (page) has a list of keywords (queries) that lead to it. Therefore, there is an association between keywords and pages that gets lost using the normal GSC Web UI download feature. You lose the granularity required to do this sort of analysis. Getting the data through the API is the only way.
The crucial first step is setting up authentication. It’s a question of throwing you down the rabbit hole abyss of OAuth authentication versus a service account.
GSC Authentication: GCP Service Account
The most common and relatively easy method for GSC authentication, especially for automated scripts, is using a Service Account. This involves creating a special account in Google Cloud Platform (GCP) and downloading a key file that your script will use to prove its identity.
Steps to Get Your Service Account Key File and Grant Access:
- Enable the API in GCP: Go to the Google Cloud Platform console, find your project (or create one), and enable the “Google Search Console API”.
- Create a Service Account:
- Navigate to “IAM & Admin” > “Service Accounts”.
- Click “Create Service Account”.
- Give it a name and description.
- Copy the generated email address (you’ll need this later).
- Grant it a role (the article uses “Owner”, though other roles might suffice).
- Generate and Download the Key File:
- Find your newly created service account in the list.
- Click the three dots menu (…) next to it and select “Manage keys”.
- Click “ADD KEY” > “Create new key”.
- Choose JSON as the key type and click “Create”.
- A
.jsonfile will download to your computer. This is your service account key file – keep it secure!
- Grant Permissions in GSC:
- Go to your Google Search Console property.
- Navigate to “Settings” > “Users and permissions”.
- Click “Add user”.
- Paste the service account email address you copied earlier.
- Set the permission level to “Full” access.
- Click “Add”.
With the downloaded .json key file and the permissions granted in GSC, your script can now authenticate and interact with the GSC API.
Getting Most Recent Date With Data in GSC
If you made it this far, then you’ve gotten over the biggest hurdle. You can
work in either a Jupyter Notebook like Google Colab or the one that comes with
Pipualte, or you can work in a plain old Python file like I’m doing in this
example, gsc_top_movers.py. The completed file can be found in the Pipulate
project at pipulate/precursors/gsc_top_movers.py, but for this article, we are
going to build it up step-by-step. I mean, they’re going to be pretty big steps.
Step 1:
#!/usr/bin/env python
# coding: utf-8
"""
Finds the most recent date for which Google Search Console (GSC) data
is available for a specified site using a service account.
Required pip installs:
pip install google-api-python-client google-auth
"""
import os
import sys
import time
from datetime import datetime, timedelta
from google.oauth2 import service_account
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
# --- Configuration ---
# Set your GSC Property URL here (e.g., "sc-domain:example.com" or "https://www.example.com/")
# IMPORTANT: Make sure the service account has access to this property!
SITE_URL = "sc-domain:mikelev.in"
# Path to your service account key JSON file
# Assumes the key file is in the same directory as the script. Adjust if needed.
SERVICE_ACCOUNT_KEY_FILE = os.path.join(os.path.dirname(__file__), 'service-account-key.json')
# Required Google API scopes
SCOPES = ['https://www.googleapis.com/auth/webmasters']
# GSC data typically has a delay. Start checking this many days before today.
START_OFFSET_DAYS = 2
# Maximum number of past days to check before giving up
MAX_DAYS_TO_CHECK = 10
# Delay between API checks (in seconds) to respect rate limits
API_CHECK_DELAY = 0.5
# --- End Configuration ---
def authenticate_gsc():
"""Authenticates with Google API using service account credentials."""
if not os.path.exists(SERVICE_ACCOUNT_KEY_FILE):
print(f"Error: Service account key file not found at: {SERVICE_ACCOUNT_KEY_FILE}")
print("Please ensure the file exists and the path is correct.")
sys.exit(1)
try:
credentials = service_account.Credentials.from_service_account_file(
SERVICE_ACCOUNT_KEY_FILE, scopes=SCOPES)
webmasters_service = build('webmasters', 'v3', credentials=credentials)
print("✓ Successfully authenticated with Google Search Console API.")
return webmasters_service
except Exception as e:
print(f"Error during GSC authentication: {e}")
sys.exit(1)
def check_date_has_data(service, site_url, check_date):
"""
Checks if GSC has any performance data for the given site and date.
Args:
service: The authenticated GSC API service object.
site_url (str): The GSC property URL.
check_date (date): The date to check for data.
Returns:
bool: True if data exists for the date, False otherwise.
"""
date_str = check_date.strftime('%Y-%m-%d')
# Create a minimal query request for the specific date
request_body = {
'startDate': date_str,
'endDate': date_str,
'dimensions': ['query'], # Using a minimal dimension
'rowLimit': 1 # We only need 1 row to confirm data exists
}
try:
# Execute the query via the searchanalytics endpoint
response = service.searchanalytics().query(
siteUrl=site_url,
body=request_body
).execute()
# Check if the 'rows' key exists and contains any data
return bool(response.get('rows')) # More concise check
except HttpError as e:
# Handle common API errors gracefully
print(f"\nAPI Error querying for date {date_str}: {e.resp.status} {e.resp.reason}")
if e.resp.status == 403:
print(" (This could be a permission issue or rate limiting.)")
elif e.resp.status == 429:
print(" (Rate limit exceeded. Consider increasing API_CHECK_DELAY.)")
# Continue checking previous days despite error on this date
return False
except Exception as e:
# Catch other potential exceptions
print(f"\nUnexpected error querying for date {date_str}: {e}")
return False
def find_most_recent_gsc_data_date(service, site_url):
"""
Iterates backward from recent dates to find the latest date with GSC data.
Args:
service: The authenticated GSC API service object.
site_url (str): The GSC property URL to check.
Returns:
date or None: The most recent date with data, or None if not found within limit.
"""
most_recent_data_date = None
days_checked = 0
current_date = datetime.now().date() - timedelta(days=START_OFFSET_DAYS)
print(f"\nFinding most recent data for site: {site_url}")
print(f"Starting check from date: {current_date}")
while days_checked < MAX_DAYS_TO_CHECK:
print(f"Checking date {current_date}...", end=" ", flush=True)
if check_date_has_data(service, site_url, current_date):
print("✓ Data found!")
most_recent_data_date = current_date
break # Exit loop once data is found
else:
print("✗ No data")
current_date -= timedelta(days=1)
days_checked += 1
time.sleep(API_CHECK_DELAY) # Pause before the next check
return most_recent_data_date
def main():
"""Main execution function."""
# 1. Authenticate and get the GSC service object
gsc_service = authenticate_gsc()
# 2. Find the most recent date with data
latest_date = find_most_recent_gsc_data_date(gsc_service, SITE_URL)
# 3. Report the result
if latest_date:
print(f"\nSuccess: Most recent GSC data available is for: {latest_date.strftime('%Y-%m-%d')}")
else:
last_checked_date = datetime.now().date() - timedelta(days=START_OFFSET_DAYS + MAX_DAYS_TO_CHECK -1)
print(f"\nWarning: Could not find GSC data within the last {MAX_DAYS_TO_CHECK} checked days")
print(f" (Checked back to {last_checked_date.strftime('%Y-%m-%d')}).")
print(" Please verify the service account has permissions for the site,")
print(" and check the GSC interface for data availability.")
if __name__ == "__main__":
# Ensure SITE_URL is set
if not SITE_URL:
print("Error: Please set the GSC_SITE_URL environment variable or update the 'SITE_URL' variable in the script.")
print("Example usage: GSC_SITE_URL=\"sc-domain:example.com\" python precursors/gsc_movers_and_shakers.py")
sys.exit(1)
main()
The glorious output of this script is a simple date, the most recent date in Google Search Console that actually has data. Many scripts out there will assume 2, 3 or 4 days ago based on assumptions, but I like to know. If the Web UI shows data up to a certain day, I want my scripts to automatically choose that same day. The only value you should have to hardwire is your domain, and even that could be brought in through the command-line args, but I’m keeping that extra code out of this (for now).
[mike@nixos:~/repos/pipulate/precursors]$ python gsc_top_movers.py
✓ Successfully authenticated with Google Search Console API.
Finding most recent data for site: sc-domain:mikelev.in
Starting check from date: 2025-04-08
Checking date 2025-04-08... ✓ Data found!
Success: Most recent GSC data available is for: 2025-04-08
Downloading Most Recent Day of GSC Data
Now the GSC API supports start and end dates and various metrics and dimensions,
and for the sake of an easy-ish example, we will start out with downloading and
putting into a Pandas DataFrame just 1-day of data from the most recent day we
just found, and ask for only the query and page dimensions. We will also
ask for the maximum rowLimit of 25000 and deliberately start at startRow 0
so we can step through and empty out all the responses into a single Python
DataFrame…
#!/usr/bin/env python
# coding: utf-8
"""
Finds the most recent date for which Google Search Console (GSC) data
is available for a specified site using a service account.
Required pip installs:
pip install google-api-python-client google-auth
"""
import os
import sys
import time
from datetime import datetime, timedelta
import pandas as pd
from google.oauth2 import service_account
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
# --- Configuration ---
# Set your GSC Property URL here (e.g., "sc-domain:example.com" or "https://www.example.com/")
# IMPORTANT: Make sure the service account has access to this property!
SITE_URL = "sc-domain:mikelev.in"
# Path to your service account key JSON file
# Assumes the key file is in the same directory as the script. Adjust if needed.
SERVICE_ACCOUNT_KEY_FILE = os.path.join(os.path.dirname(__file__), 'service-account-key.json')
# Required Google API scopes
SCOPES = ['https://www.googleapis.com/auth/webmasters']
# GSC data typically has a delay. Start checking this many days before today.
START_OFFSET_DAYS = 2
# Maximum number of past days to check before giving up
MAX_DAYS_TO_CHECK = 10
# Delay between API checks (in seconds) to respect rate limits
API_CHECK_DELAY = 0.5
# --- End Configuration ---
def authenticate_gsc():
"""Authenticates with Google API using service account credentials."""
if not os.path.exists(SERVICE_ACCOUNT_KEY_FILE):
print(f"Error: Service account key file not found at: {SERVICE_ACCOUNT_KEY_FILE}")
print("Please ensure the file exists and the path is correct.")
sys.exit(1)
try:
credentials = service_account.Credentials.from_service_account_file(
SERVICE_ACCOUNT_KEY_FILE, scopes=SCOPES)
webmasters_service = build('webmasters', 'v3', credentials=credentials)
print("✓ Successfully authenticated with Google Search Console API.")
return webmasters_service
except Exception as e:
print(f"Error during GSC authentication: {e}")
sys.exit(1)
def check_date_has_data(service, site_url, check_date):
"""
Checks if GSC has any performance data for the given site and date.
Args:
service: The authenticated GSC API service object.
site_url (str): The GSC property URL.
check_date (date): The date to check for data.
Returns:
bool: True if data exists for the date, False otherwise.
"""
date_str = check_date.strftime('%Y-%m-%d')
# Create a minimal query request for the specific date
request_body = {
'startDate': date_str,
'endDate': date_str,
'dimensions': ['query'], # Using a minimal dimension
'rowLimit': 1 # We only need 1 row to confirm data exists
}
try:
# Execute the query via the searchanalytics endpoint
response = service.searchanalytics().query(
siteUrl=site_url,
body=request_body
).execute()
# Check if the 'rows' key exists and contains any data
return bool(response.get('rows')) # More concise check
except HttpError as e:
# Handle common API errors gracefully
print(f"\nAPI Error querying for date {date_str}: {e.resp.status} {e.resp.reason}")
if e.resp.status == 403:
print(" (This could be a permission issue or rate limiting.)")
elif e.resp.status == 429:
print(" (Rate limit exceeded. Consider increasing API_CHECK_DELAY.)")
# Continue checking previous days despite error on this date
return False
except Exception as e:
# Catch other potential exceptions
print(f"\nUnexpected error querying for date {date_str}: {e}")
return False
def find_most_recent_gsc_data_date(service, site_url):
"""
Iterates backward from recent dates to find the latest date with GSC data.
Args:
service: The authenticated GSC API service object.
site_url (str): The GSC property URL to check.
Returns:
date or None: The most recent date with data, or None if not found within limit.
"""
most_recent_data_date = None
days_checked = 0
current_date = datetime.now().date() - timedelta(days=START_OFFSET_DAYS)
print(f"\nFinding most recent data for site: {site_url}")
print(f"Starting check from date: {current_date}")
while days_checked < MAX_DAYS_TO_CHECK:
print(f"Checking date {current_date}...", end=" ", flush=True)
if check_date_has_data(service, site_url, current_date):
print("✓ Data found!")
most_recent_data_date = current_date
break # Exit loop once data is found
else:
print("✗ No data")
current_date -= timedelta(days=1)
days_checked += 1
time.sleep(API_CHECK_DELAY) # Pause before the next check
return most_recent_data_date
def fetch_all_gsc_data(service, site_url, request_body):
"""
Fetches all available data rows for a given GSC query, handling pagination.
Args:
service: The authenticated GSC API service object.
site_url (str): The GSC property URL.
request_body (dict): The initial query request body. Must include
'rowLimit' and 'startRow'.
Returns:
list: A list containing all the row data dictionaries fetched from GSC.
Returns an empty list if an error occurs or no data is found.
"""
all_rows = []
start_row = request_body.get('startRow', 0)
row_limit = request_body.get('rowLimit', 1000) # Default GSC limit if not specified
page_count = 0
print(f"\nFetching data with dimensions: {request_body.get('dimensions', [])}")
while True:
page_count += 1
request_body['startRow'] = start_row
print(f"Fetching page {page_count} (starting row {start_row})...", end=" ", flush=True)
try:
response = service.searchanalytics().query(
siteUrl=site_url,
body=request_body
).execute()
current_rows = response.get('rows', [])
if not current_rows:
if page_count == 1:
print("No data found for this query.")
else:
print("✓ No more data.")
break # Exit loop if no rows are returned
print(f"✓ Retrieved {len(current_rows)} rows.")
all_rows.extend(current_rows)
# GSC API max rowLimit is 25000, but let's use the requested rowLimit
# If fewer rows than the limit are returned, it's the last page
if len(current_rows) < row_limit:
print("✓ Reached last page of results.")
break # Exit loop if last page is fetched
start_row += len(current_rows)
time.sleep(API_CHECK_DELAY) # Be nice to the API between pages
except HttpError as e:
print(f"\nAPI Error during data fetch (page {page_count}): {e.resp.status} {e.resp.reason}")
if e.resp.status in [403, 429]:
print(" (Consider permissions, quotas, or increasing API_CHECK_DELAY.)")
print(" Aborting data fetch for this request.")
return [] # Return empty list on error
except Exception as e:
print(f"\nUnexpected error during data fetch (page {page_count}): {e}")
print(" Aborting data fetch for this request.")
return [] # Return empty list on error
print(f"✓ Finished fetching. Total rows retrieved: {len(all_rows)}")
return all_rows
def process_gsc_data_to_dataframe(gsc_data_list):
"""
Converts the raw list of GSC data rows into a processed Pandas DataFrame.
Args:
gsc_data_list (list): A list of row data dictionaries from fetch_all_gsc_data.
Returns:
pandas.DataFrame: A DataFrame with processed GSC data, including separate
'query' and 'page' columns, and numeric metrics.
Returns an empty DataFrame if input is empty or invalid.
"""
if not gsc_data_list:
print("No data to process into DataFrame.")
return pd.DataFrame()
df = pd.DataFrame(gsc_data_list)
# Split the 'keys' column (list) into separate dimension columns
if 'keys' in df.columns and not df['keys'].empty:
# Assuming dimensions are ['query', 'page'] as requested
try:
df['query'] = df['keys'].apply(lambda x: x[0] if isinstance(x, list) and len(x) > 0 else None)
df['page'] = df['keys'].apply(lambda x: x[1] if isinstance(x, list) and len(x) > 1 else None)
df = df.drop('keys', axis=1)
print("✓ Split 'keys' into 'query' and 'page' columns.")
except Exception as e:
print(f"Warning: Could not split 'keys' column reliably: {e}")
# Keep the 'keys' column if splitting fails
if 'query' in df.columns:
df = df.drop('query', axis=1)
if 'page' in df.columns:
df = df.drop('page', axis=1)
# Ensure standard metric columns exist and convert to numeric types
metric_cols = ['clicks', 'impressions', 'ctr', 'position']
for col in metric_cols:
if col in df.columns:
df[col] = pd.to_numeric(df[col], errors='coerce') # Coerce errors to NaN
# Optional: Fill NaNs created by coercion if needed, e.g., df[col] = df[col].fillna(0)
else:
# Add the column with default value if missing (optional)
# df[col] = 0
print(f"Note: Metric column '{col}' not found in raw data.")
# Optional: Convert CTR to percentage for display
if 'ctr' in df.columns:
df['ctr'] = df['ctr'] * 100
print("✓ Converted 'ctr' to percentage.")
print(f"✓ Processed data into DataFrame with {len(df)} rows and {len(df.columns)} columns.")
return df
def main():
"""Main execution function."""
# 1. Authenticate and get the GSC service object
gsc_service = authenticate_gsc()
# 2. Find the most recent date with data
latest_date = find_most_recent_gsc_data_date(gsc_service, SITE_URL)
# --- ADD THE FOLLOWING ---
# 3. If a date was found, fetch and process the data for that day
if latest_date:
print(f"\nAttempting to download data for the most recent date: {latest_date.strftime('%Y-%m-%d')}")
# Define the request for that single day
single_day_request = {
'startDate': latest_date.strftime('%Y-%m-%d'),
'endDate': latest_date.strftime('%Y-%m-%d'),
'dimensions': ['query', 'page'],
'rowLimit': 25000, # Use max row limit per page fetch
'startRow': 0
}
# Fetch data using the pagination function
raw_gsc_data = fetch_all_gsc_data(gsc_service, SITE_URL, single_day_request)
# Process the raw data into a DataFrame
df_gsc_data = process_gsc_data_to_dataframe(raw_gsc_data)
# Display results if DataFrame is not empty
if not df_gsc_data.empty:
print("\n--- GSC Data DataFrame Preview (first 10 rows) ---")
# Set display options for better preview
pd.set_option('display.max_rows', 20)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 100)
pd.set_option('display.max_colwidth', 50)
print(df_gsc_data.head(10))
print("\n--- DataFrame Info ---")
df_gsc_data.info()
print("\n--- Basic Stats ---")
# Use describe() for numeric columns, handle potential missing columns
numeric_cols = df_gsc_data.select_dtypes(include=['number']).columns
if not numeric_cols.empty:
print(df_gsc_data[numeric_cols].describe())
else:
print("No numeric columns found for describe().")
# Example of accessing specific data
# print(f"\nTotal Clicks: {df_gsc_data['clicks'].sum()}")
# print(f"Total Impressions: {df_gsc_data['impressions'].sum()}")
else:
print("\nNo data was processed into the DataFrame.")
# --- END OF ADDED SECTION ---
else:
# This part was already there: handle case where no date was found
last_checked_date = datetime.now().date() - timedelta(days=START_OFFSET_DAYS + MAX_DAYS_TO_CHECK - 1)
print(f"\nWarning: Could not find GSC data within the last {MAX_DAYS_TO_CHECK} checked days")
print(f" (Checked back to {last_checked_date.strftime('%Y-%m-%d')}).")
print(" Cannot proceed with data download.")
# Removed the previous permission/interface check message as it's less relevant here
# --- Ensure the final block still calls main() ---
if __name__ == "__main__":
# Ensure SITE_URL is set (this check can be simplified or enhanced)
if not SITE_URL or SITE_URL == "sc-domain:yourdomain.com": # Added check for default placeholder
print("Error: Please update the 'SITE_URL' variable in the script configuration.")
sys.exit(1)
main()
The first program has been expanded with a number of functions added and a
reworking of the main function. Here’s the explanation.
- Import pandas: We add
import pandas as pdat the top to handle data manipulation. Workspace_all_gsc_datafunction: This function is crucial. It takes the initial request and repeatedly calls the GSC API, increasing thestartRoweach time, until all data matching the request (for the specified date and dimensions) is collected. It includes basic error handling and delays between calls.process_gsc_data_to_dataframefunction: This takes the raw list of data returned by the API and transforms it into a structured Pandas DataFrame. It splits thekeyslist into properqueryandpagecolumns and ensures the metric columns (clicks,impressions,ctr,position) are numeric.- Updated
mainfunction:- After successfully finding the
latest_date, it defines asingle_day_requestdictionary using that date for bothstartDateandendDate, specifying the desireddimensions, and setting the maximumrowLimit. - It calls
Workspace_all_gsc_datato get the raw data. - It calls
process_gsc_data_to_dataframeto structure the data. - Finally, if data was successfully processed, it prints a preview of the DataFrame using
df_gsc_data.head(10)and shows basic info and stats usingdf_gsc_data.info()anddf_gsc_data.describe().
- After successfully finding the
Running The 1-Day Version of GSC Script
We’re building-up here. I know it’s a lot of code to look at. But this will let you build-up the same way, going from basic GSC access that finds the first day of data, to downloading the data for that day.
Now, running the script will not only find the most recent date but also download and display the query and page performance data for that specific day.
[mike@nixos:~/repos/pipulate/precursors]$ python gsc_top_movers.py
✓ Successfully authenticated with Google Search Console API.
Finding most recent data for site: sc-domain:mikelev.in
Starting check from date: 2025-04-08
Checking date 2025-04-08... ✓ Data found!
Attempting to download data for the most recent date: 2025-04-08
Fetching data with dimensions: ['query', 'page']
Fetching page 1 (starting row 0)... ✓ Retrieved 3261 rows.
✓ Reached last page of results.
✓ Finished fetching. Total rows retrieved: 3261
✓ Split 'keys' into 'query' and 'page' columns.
✓ Converted 'ctr' to percentage.
✓ Processed data into DataFrame with 3261 rows and 6 columns.
--- GSC Data DataFrame Preview (first 10 rows) ---
clicks impressions ctr position query \
0 2 9 22.222222 11.111111 cursor jupyter notebook
1 1 27 3.703704 41.851852 cursor ai
2 1 2 50.000000 3.500000 cursor ai jupyter
3 1 2 50.000000 7.000000 cursor and jupyter notebook
4 1 1 100.000000 2.000000 fasthtml
5 1 3 33.333333 25.666667 fasthtml
6 1 1 100.000000 23.000000 function calling in llms
7 1 3 33.333333 1.000000 grok markdown
8 1 3 33.333333 7.000000 how to run jupyter notebook in cursor
9 1 7 14.285714 4.285714 nix flake python
page
0 https://mikelev.in/futureproof/jupyter-noteboo...
1 https://mikelev.in/futureproof/ai-agentic-mode...
2 https://mikelev.in/futureproof/jupyter-noteboo...
3 https://mikelev.in/futureproof/jupyter-noteboo...
4 https://mikelev.in/futureproof/foo/
5 https://mikelev.in/futureproof/unpacking-fasth...
6 https://mikelev.in/futureproof/function-callin...
7 https://mikelev.in/futureproof/grok3-markdown-...
8 https://mikelev.in/futureproof/jupyter-noteboo...
9 https://mikelev.in/futureproof/nix-flakes/
--- DataFrame Info ---
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3261 entries, 0 to 3260
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 clicks 3261 non-null int64
1 impressions 3261 non-null int64
2 ctr 3261 non-null float64
3 position 3261 non-null float64
4 query 3261 non-null object
5 page 3261 non-null object
dtypes: float64(2), int64(2), object(2)
memory usage: 153.0+ KB
--- Basic Stats ---
clicks impressions ctr position
count 3261.000000 3261.000000 3261.000000 3261.000000
mean 0.003680 1.697639 0.165658 74.311338
std 0.065429 2.811669 3.456809 23.902479
min 0.000000 1.000000 0.000000 1.000000
25% 0.000000 1.000000 0.000000 64.000000
50% 0.000000 1.000000 0.000000 80.000000
75% 0.000000 2.000000 0.000000 92.000000
max 2.000000 87.000000 100.000000 194.000000
Downloading 4 Individual Days of GSC Data
Now the beautiful thing here is that because all our data is for a particular day which so happens to be the most recent day that has GSC data, we can start to gather the data we need for really beautiful directional analysis per keyword per URL. In GSC parlance, keyword is query and URL is page. So what we do next is subtract 1 day from the date, and do the same thing we just did.
In fact, we can have a day-range and create a Pandas DataFrame for each day, N-days back from the most recent that has data. For the sake of simplicity and being kind to your computer’s memory, we will only do 3 days back total, for a total of 4 days worth of data, or 4 separate Pandas DataFrames.
Here’s how we do that…
#!/usr/bin/env python
# coding: utf-8
"""
Fetches Google Search Console (GSC) data for the 4 most recent days available
for a specified site using a service account. Saves each day to a CSV file.
Required pip installs:
pip install google-api-python-client google-auth pandas
"""
import os
import sys
import time
from datetime import datetime, timedelta
import pandas as pd
from google.oauth2 import service_account
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
# --- Configuration ---
# Set your GSC Property URL here (e.g., "sc-domain:example.com" or "https://www.example.com/")
SITE_URL = "sc-domain:mikelev.in"
# Path to your service account key JSON file
# Assumes the key file is in the same directory as the script. Adjust if needed.
SCRIPT_DIR = os.path.dirname(__file__)
SERVICE_ACCOUNT_KEY_FILE = os.path.join(SCRIPT_DIR, 'service-account-key.json')
# Required Google API scopes
SCOPES = ['https://www.googleapis.com/auth/webmasters']
# GSC data typically has a delay. Start checking this many days before today.
START_OFFSET_DAYS = 2
# Maximum number of past days to check before giving up
MAX_DAYS_TO_CHECK = 10
# Delay between API checks (in seconds) to respect rate limits
API_CHECK_DELAY = 0.5
# Number of consecutive days of data to fetch (ending on the most recent date)
NUM_DAYS_TO_FETCH = 4
# Directory to store/load cached daily GSC data CSV files
CACHE_DIR = os.path.join(SCRIPT_DIR, 'gsc_cache')
# --- End Configuration ---
def authenticate_gsc():
"""Authenticates with Google API using service account credentials."""
if not os.path.exists(SERVICE_ACCOUNT_KEY_FILE):
print(f"Error: Service account key file not found at: {SERVICE_ACCOUNT_KEY_FILE}")
print("Please ensure the file exists and the path is correct.")
sys.exit(1)
try:
credentials = service_account.Credentials.from_service_account_file(
SERVICE_ACCOUNT_KEY_FILE, scopes=SCOPES)
webmasters_service = build('webmasters', 'v3', credentials=credentials)
print("✓ Successfully authenticated with Google Search Console API.")
return webmasters_service
except Exception as e:
print(f"Error during GSC authentication: {e}")
sys.exit(1)
def check_date_has_data(service, site_url, check_date):
"""Checks if GSC has any performance data for the given site and date."""
date_str = check_date.strftime('%Y-%m-%d')
request_body = {
'startDate': date_str, 'endDate': date_str,
'dimensions': ['query'], 'rowLimit': 1
}
try:
response = service.searchanalytics().query(
siteUrl=site_url, body=request_body).execute()
return bool(response.get('rows'))
except HttpError as e:
print(f"\nAPI Error checking date {date_str}: {e.resp.status} {e.resp.reason}")
return False
except Exception as e:
print(f"\nUnexpected error checking date {date_str}: {e}")
return False
def find_most_recent_gsc_data_date(service, site_url):
"""Iterates backward to find the latest date with GSC data."""
most_recent_data_date = None
days_checked = 0
current_date = datetime.now().date() - timedelta(days=START_OFFSET_DAYS)
print(f"\nFinding most recent data date for site: {site_url}")
print(f"Starting check from date: {current_date}")
while days_checked < MAX_DAYS_TO_CHECK:
print(f"Checking date {current_date}...", end=" ", flush=True)
if check_date_has_data(service, site_url, current_date):
print("✓ Data found!")
most_recent_data_date = current_date
break
else:
print("✗ No data")
current_date -= timedelta(days=1)
days_checked += 1
time.sleep(API_CHECK_DELAY)
if not most_recent_data_date:
last_checked_date = current_date + timedelta(days=1) # Date where check stopped
print(f"\nWarning: Could not find data within {MAX_DAYS_TO_CHECK} checked days (back to {last_checked_date}).")
return most_recent_data_date
def fetch_all_gsc_data(service, site_url, request_body):
"""Fetches all available data rows for a given GSC query, handling pagination."""
all_rows = []
start_row = request_body.get('startRow', 0)
row_limit = request_body.get('rowLimit', 25000) # Use max GSC limit
page_count = 0
print(f"\nFetching data with dimensions: {request_body.get('dimensions', [])} for {request_body.get('startDate')}")
while True:
page_count += 1
request_body['startRow'] = start_row
print(f"Fetching page {page_count} (starting row {start_row})...", end=" ", flush=True)
try:
response = service.searchanalytics().query(
siteUrl=site_url, body=request_body).execute()
current_rows = response.get('rows', [])
if not current_rows:
if page_count == 1: print("No data found for this query.")
else: print("✓ No more data.")
break
print(f"✓ Retrieved {len(current_rows)} rows.")
all_rows.extend(current_rows)
if len(current_rows) < row_limit:
print("✓ Reached last page of results.")
break
start_row += len(current_rows)
time.sleep(API_CHECK_DELAY)
except HttpError as e:
print(f"\nAPI Error fetching page {page_count}: {e.resp.status} {e.resp.reason}")
return [] # Return empty list on error
except Exception as e:
print(f"\nUnexpected error fetching page {page_count}: {e}")
return []
print(f"✓ Finished fetching {request_body.get('startDate')}. Total rows: {len(all_rows)}")
return all_rows
def process_gsc_data_to_dataframe(gsc_data_list, data_date):
"""Converts raw GSC data list into a processed Pandas DataFrame."""
if not gsc_data_list:
print(f"No data to process into DataFrame for {data_date}.")
return pd.DataFrame()
df = pd.DataFrame(gsc_data_list)
if 'keys' in df.columns and not df['keys'].empty:
try:
df['query'] = df['keys'].apply(lambda x: x[0] if isinstance(x, list) and len(x) > 0 else None)
df['page'] = df['keys'].apply(lambda x: x[1] if isinstance(x, list) and len(x) > 1 else None)
df = df.drop('keys', axis=1)
except Exception as e:
print(f"Warning: Could not split 'keys' column for {data_date}: {e}")
metric_cols = ['clicks', 'impressions', 'ctr', 'position']
for col in metric_cols:
if col in df.columns:
df[col] = pd.to_numeric(df[col], errors='coerce')
else:
print(f"Note: Metric column '{col}' not found for {data_date}.")
if 'ctr' in df.columns: df['ctr'] = df['ctr'] * 100
print(f"✓ Processed data for {data_date} into DataFrame ({len(df)} rows).")
return df
def get_gsc_data_for_day(service, site_url, data_date):
"""
Fetches GSC data for a specific day, using cache if available.
Args:
service: Authenticated GSC service object.
site_url (str): Target GSC property URL.
data_date (date): The specific date to fetch data for.
Returns:
pandas.DataFrame: DataFrame containing data for the specified date.
Returns an empty DataFrame if fetching fails or no data.
"""
date_str = data_date.strftime('%Y-%m-%d')
cache_filename = os.path.join(CACHE_DIR, f"gsc_data_{date_str}.csv")
# Check cache first
if os.path.exists(cache_filename):
try:
print(f"✓ Loading data for {date_str} from cache: {cache_filename}")
# Specify dtypes to avoid warnings and ensure consistency
df = pd.read_csv(cache_filename, dtype={
'clicks': 'Int64', # Use nullable integer type
'impressions': 'Int64',
'ctr': 'float64',
'position': 'float64',
'query': 'object',
'page': 'object'
}, parse_dates=False) # Dates handled separately
# Ensure CTR is percentage if loaded from CSV
if 'ctr' in df.columns and df['ctr'].max() <= 1.0:
df['ctr'] = df['ctr'] * 100
return df
except Exception as e:
print(f"Warning: Could not load cache file {cache_filename}. Error: {e}. Re-fetching.")
# If not in cache or cache fails, fetch from API
print(f"Fetching data for {date_str} from GSC API...")
request = {
'startDate': date_str, 'endDate': date_str,
'dimensions': ['query', 'page'],
'rowLimit': 25000, 'startRow': 0
}
raw_data = fetch_all_gsc_data(service, site_url, request)
df = process_gsc_data_to_dataframe(raw_data, date_str)
# Save to cache if data was fetched successfully and is not empty
if not df.empty:
try:
os.makedirs(CACHE_DIR, exist_ok=True) # Ensure cache directory exists
df.to_csv(cache_filename, index=False)
print(f"✓ Saved data for {date_str} to cache: {cache_filename}")
except Exception as e:
print(f"Warning: Could not save data for {date_str} to cache. Error: {e}")
return df
def main():
"""Main execution function."""
# 1. Authenticate and get the GSC service object
gsc_service = authenticate_gsc()
# 2. Find the most recent date with data
latest_date = find_most_recent_gsc_data_date(gsc_service, SITE_URL)
if not latest_date:
print("\nCannot proceed without a valid recent date.")
sys.exit(1)
print(f"\nSuccess: Most recent GSC data available is for: {latest_date.strftime('%Y-%m-%d')}")
# 3. Determine the date range (last NUM_DAYS_TO_FETCH days)
dates_to_fetch = [latest_date - timedelta(days=i) for i in range(NUM_DAYS_TO_FETCH)][::-1] # Reverse to get oldest first
print(f"\nPreparing to fetch/load data for {NUM_DAYS_TO_FETCH} days:")
for d in dates_to_fetch:
print(f" - {d.strftime('%Y-%m-%d')}")
# 4. Fetch/load data for each day into a dictionary of DataFrames
daily_dataframes = {}
all_data_fetched = True
for target_date in dates_to_fetch:
df_day = get_gsc_data_for_day(gsc_service, SITE_URL, target_date)
if df_day.empty and not os.path.exists(os.path.join(CACHE_DIR, f"gsc_data_{target_date.strftime('%Y-%m-%d')}.csv")):
# Check if the file exists even if df is empty, maybe it was an empty day
print(f"Warning: Failed to fetch or load data for {target_date.strftime('%Y-%m-%d')}. Trend analysis might be incomplete.")
all_data_fetched = False
daily_dataframes[target_date] = df_day
# 5. Confirmation and next steps preview
if all_data_fetched:
print(f"\n✓ Successfully fetched/loaded data for all {len(daily_dataframes)} target days.")
# Optionally display info about one of the DataFrames
if latest_date in daily_dataframes and not daily_dataframes[latest_date].empty:
print(f"\n--- Preview of data for the latest date ({latest_date.strftime('%Y-%m-%d')}): ---")
print(daily_dataframes[latest_date].head())
print(f"(Total rows for {latest_date.strftime('%Y-%m-%d')}: {len(daily_dataframes[latest_date])})")
print("\nDataFrames are stored in the 'daily_dataframes' dictionary, keyed by date.")
print("Next step: Combine these DataFrames and perform trend analysis.")
else:
print("\nWarning: Data fetching/loading was incomplete for one or more days.")
print("Proceeding with available data, but trend analysis might be affected.")
# Still print available data info
print(f"\nAvailable DataFrames ({len(daily_dataframes)}): {list(daily_dataframes.keys())}")
# The script now ends here. The next logical step (trend analysis)
# would follow, using the 'daily_dataframes' dictionary.
if __name__ == "__main__":
if not SITE_URL or SITE_URL == "sc-domain:yourdomain.com":
print("Error: Please update the 'SITE_URL' variable in the script configuration.")
sys.exit(1)
main()
Explanation of Changes:
- Configuration: Added
NUM_DAYS_TO_FETCH(set to 4) andCACHE_DIRvariables. get_gsc_data_for_dayFunction: This new function encapsulates the logic for getting data for a single specific date.- It constructs the expected cache filename (
gsc_data_YYYY-MM-DD.csv) inside theCACHE_DIR. - It first checks if this file exists. If yes, it loads the data using
pd.read_csv(specifying dtypes for robustness) and returns the DataFrame. - If the file doesn’t exist (or loading fails), it proceeds to call
Workspace_all_gsc_datato get data from the API. - It then calls
process_gsc_data_to_dataframe. - If the fetched data is not empty, it saves the DataFrame to the cache file using
df.to_csv(index=False). - It returns the resulting DataFrame (which might be empty if fetching failed or the day truly had no data).
- It constructs the expected cache filename (
- Updated
mainFunction:- After finding
latest_date, it calculates the list ofdates_to_fetch(the 4 days ending onlatest_date). - It initializes an empty dictionary
daily_dataframesto store the results. - It loops through
dates_to_fetch. In each iteration:- It calls
get_gsc_data_for_dayfor the current date. - It stores the returned DataFrame in the
daily_dataframesdictionary, using the date object as the key. - It includes a basic check (
all_data_fetched) to see if data was obtained for all requested days.
- It calls
- After the loop, it prints a confirmation message and a preview of the data for the most recent day. It explicitly mentions that the data is now ready for the next step (trend analysis) and stored in the
daily_dataframesdictionary.
- After finding
Now, when you run this script, it will fetch (or load from cache) the data for each of the last 4 days and store them in memory, ready for the trend analysis code you outlined previously.
Here’s sample output:
[mike@nixos:~/repos/pipulate/precursors]$ python gsc_top_movers.py
✓ Successfully authenticated with Google Search Console API.
Finding most recent data date for site: sc-domain:mikelev.in
Starting check from date: 2025-04-08
Checking date 2025-04-08... ✓ Data found!
Success: Most recent GSC data available is for: 2025-04-08
Preparing to fetch/load data for 4 days:
- 2025-04-05
- 2025-04-06
- 2025-04-07
- 2025-04-08
Fetching data for 2025-04-05 from GSC API...
Fetching data with dimensions: ['query', 'page'] for 2025-04-05
Fetching page 1 (starting row 0)... ✓ Retrieved 214 rows.
✓ Reached last page of results.
✓ Finished fetching 2025-04-05. Total rows: 214
✓ Processed data for 2025-04-05 into DataFrame (214 rows).
✓ Saved data for 2025-04-05 to cache: /home/mike/repos/pipulate/precursors/gsc_cache/gsc_data_2025-04-05.csv
Fetching data for 2025-04-06 from GSC API...
Fetching data with dimensions: ['query', 'page'] for 2025-04-06
Fetching page 1 (starting row 0)... ✓ Retrieved 223 rows.
✓ Reached last page of results.
✓ Finished fetching 2025-04-06. Total rows: 223
✓ Processed data for 2025-04-06 into DataFrame (223 rows).
✓ Saved data for 2025-04-06 to cache: /home/mike/repos/pipulate/precursors/gsc_cache/gsc_data_2025-04-06.csv
Fetching data for 2025-04-07 from GSC API...
Fetching data with dimensions: ['query', 'page'] for 2025-04-07
Fetching page 1 (starting row 0)... ✓ Retrieved 1791 rows.
✓ Reached last page of results.
✓ Finished fetching 2025-04-07. Total rows: 1791
✓ Processed data for 2025-04-07 into DataFrame (1791 rows).
✓ Saved data for 2025-04-07 to cache: /home/mike/repos/pipulate/precursors/gsc_cache/gsc_data_2025-04-07.csv
Fetching data for 2025-04-08 from GSC API...
Fetching data with dimensions: ['query', 'page'] for 2025-04-08
Fetching page 1 (starting row 0)... ✓ Retrieved 3261 rows.
✓ Reached last page of results.
✓ Finished fetching 2025-04-08. Total rows: 3261
✓ Processed data for 2025-04-08 into DataFrame (3261 rows).
✓ Saved data for 2025-04-08 to cache: /home/mike/repos/pipulate/precursors/gsc_cache/gsc_data_2025-04-08.csv
✓ Successfully fetched/loaded data for all 4 target days.
--- Preview of data for the latest date (2025-04-08): ---
clicks impressions ctr position query page
0 2 9 22.222222 11.111111 cursor jupyter notebook https://mikelev.in/futureproof/jupyter-noteboo...
1 1 27 3.703704 41.851852 cursor ai https://mikelev.in/futureproof/ai-agentic-mode...
2 1 2 50.000000 3.500000 cursor ai jupyter https://mikelev.in/futureproof/jupyter-noteboo...
3 1 2 50.000000 7.000000 cursor and jupyter notebook https://mikelev.in/futureproof/jupyter-noteboo...
4 1 1 100.000000 2.000000 fasthtml https://mikelev.in/futureproof/foo/
(Total rows for 2025-04-08: 3261)
DataFrames are stored in the 'daily_dataframes' dictionary, keyed by date.
Next step: Combine these DataFrames and perform trend analysis.
Top Movers & Shakers Directional Trending
Now you may be asking why go through all the trouble of downloading 4 individual days of GSC data when you could have just given a date-range starting from 3-days prior to the first day that has data. The answer is that we now have enough granular per-day data to do trend-lines! If you’re an Excel wonk, that’s sparklines to you. And if you’re a stats geek, that’s enough to calculate the linear regression coefficient slope. A steep positive slope shows sudden upward movement. And so, we will be joining all 4 of our dataframes and adding a linear regression coefficient slope column like so…
Top Movers & Shakers Directional Trending
Now you may be asking why go through all the trouble of downloading 4 individual days of GSC data when you could have just given a date-range starting from 3-days prior to the first day that has data. The answer is that we now have enough granular per-day data to do trend-lines! If you’re an Excel wonk, that’s sparklines to you. And if you’re a stats geek, that’s enough to calculate the linear regression coefficient slope. A steep positive slope shows sudden upward movement. And so, we will be joining all 4 of our dataframes and adding a linear regression coefficient slope column.
This final version of the script takes the daily_dataframes dictionary (containing the data for our 4 chosen days, loaded either from the cache or fetched via the API) and performs the core trend analysis.
Here is the complete, final script (gsc_top_movers.py):
#!/usr/bin/env python
# coding: utf-8
"""
Fetches Google Search Console (GSC) data for the 4 most recent days available,
calculates trend slopes for impressions, clicks, and position for each
page/query combination, and identifies top movers. Saves daily data to CSV cache.
Required pip installs:
pip install google-api-python-client google-auth pandas numpy scipy
"""
import os
import sys
import time
from datetime import datetime, timedelta
import numpy as np
import pandas as pd
from google.oauth2 import service_account
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
# Need scipy for linregress OR numpy for polyfit - we'll use polyfit here
# from scipy.stats import linregress
# --- Configuration ---
# Set your GSC Property URL here (e.g., "sc-domain:example.com" or "https://www.example.com/")
SITE_URL = "sc-domain:mikelev.in"
# Path to your service account key JSON file
# Assumes the key file is in the same directory as the script. Adjust if needed.
SCRIPT_DIR = os.path.dirname(__file__)
SERVICE_ACCOUNT_KEY_FILE = os.path.join(SCRIPT_DIR, 'service-account-key.json')
# Required Google API scopes
SCOPES = ['https://www.googleapis.com/auth/webmasters']
# GSC data typically has a delay. Start checking this many days before today.
START_OFFSET_DAYS = 2
# Maximum number of past days to check before giving up
MAX_DAYS_TO_CHECK = 10
# Delay between API checks (in seconds) to respect rate limits
API_CHECK_DELAY = 0.5
# Number of consecutive days of data to fetch (ending on the most recent date)
NUM_DAYS_TO_FETCH = 4
# Directory to store/load cached daily GSC data CSV files
CACHE_DIR = os.path.join(SCRIPT_DIR, 'gsc_cache')
# --- End Configuration ---
# --- Functions from previous steps (authenticate_gsc, check_date_has_data, find_most_recent_gsc_data_date, fetch_all_gsc_data, process_gsc_data_to_dataframe, get_gsc_data_for_day) ---
# Include the full definitions of these functions here from the previous code block...
def authenticate_gsc():
"""Authenticates with Google API using service account credentials."""
if not os.path.exists(SERVICE_ACCOUNT_KEY_FILE):
print(f"Error: Service account key file not found at: {SERVICE_ACCOUNT_KEY_FILE}")
sys.exit(1)
try:
credentials = service_account.Credentials.from_service_account_file(
SERVICE_ACCOUNT_KEY_FILE, scopes=SCOPES)
webmasters_service = build('webmasters', 'v3', credentials=credentials)
print("✓ Successfully authenticated with Google Search Console API.")
return webmasters_service
except Exception as e:
print(f"Error during GSC authentication: {e}")
sys.exit(1)
def check_date_has_data(service, site_url, check_date):
"""Checks if GSC has any performance data for the given site and date."""
date_str = check_date.strftime('%Y-%m-%d')
request_body = {
'startDate': date_str, 'endDate': date_str,
'dimensions': ['query'], 'rowLimit': 1
}
try:
response = service.searchanalytics().query(
siteUrl=site_url, body=request_body).execute()
return bool(response.get('rows'))
except HttpError as e:
print(f"\nAPI Error checking date {date_str}: {e.resp.status} {e.resp.reason}")
return False
except Exception as e:
print(f"\nUnexpected error checking date {date_str}: {e}")
return False
def find_most_recent_gsc_data_date(service, site_url):
"""Iterates backward to find the latest date with GSC data."""
most_recent_data_date = None
days_checked = 0
current_date = datetime.now().date() - timedelta(days=START_OFFSET_DAYS)
print(f"\nFinding most recent data date for site: {site_url}")
print(f"Starting check from date: {current_date}")
while days_checked < MAX_DAYS_TO_CHECK:
print(f"Checking date {current_date}...", end=" ", flush=True)
if check_date_has_data(service, site_url, current_date):
print("✓ Data found!")
most_recent_data_date = current_date
break
else:
print("✗ No data")
current_date -= timedelta(days=1)
days_checked += 1
time.sleep(API_CHECK_DELAY)
if not most_recent_data_date:
last_checked_date = current_date + timedelta(days=1) # Date where check stopped
print(f"\nWarning: Could not find data within {MAX_DAYS_TO_CHECK} checked days (back to {last_checked_date}).")
return most_recent_data_date
def fetch_all_gsc_data(service, site_url, request_body):
"""Fetches all available data rows for a given GSC query, handling pagination."""
all_rows = []
start_row = request_body.get('startRow', 0)
row_limit = request_body.get('rowLimit', 25000) # Use max GSC limit
page_count = 0
print(f"\nFetching data with dimensions: {request_body.get('dimensions', [])} for {request_body.get('startDate')}")
while True:
page_count += 1
request_body['startRow'] = start_row
print(f"Fetching page {page_count} (starting row {start_row})...", end=" ", flush=True)
try:
response = service.searchanalytics().query(
siteUrl=site_url, body=request_body).execute()
current_rows = response.get('rows', [])
if not current_rows:
if page_count == 1:
print("No data found for this query.")
else:
print("✓ No more data.")
break
print(f"✓ Retrieved {len(current_rows)} rows.")
all_rows.extend(current_rows)
if len(current_rows) < row_limit:
print("✓ Reached last page of results.")
break
start_row += len(current_rows)
time.sleep(API_CHECK_DELAY)
except HttpError as e:
print(f"\nAPI Error fetching page {page_count}: {e.resp.status} {e.resp.reason}")
return [] # Return empty list on error
except Exception as e:
print(f"\nUnexpected error fetching page {page_count}: {e}")
return []
print(f"✓ Finished fetching {request_body.get('startDate')}. Total rows: {len(all_rows)}")
return all_rows
def process_gsc_data_to_dataframe(gsc_data_list, data_date):
"""Converts raw GSC data list into a processed Pandas DataFrame."""
if not gsc_data_list:
# Keep this print statement for clarity during processing
# print(f"No data to process into DataFrame for {data_date}.")
return pd.DataFrame() # Return empty DF if no raw data
df = pd.DataFrame(gsc_data_list)
if 'keys' in df.columns and not df['keys'].empty:
try:
df['query'] = df['keys'].apply(lambda x: x[0] if isinstance(x, list) and len(x) > 0 else None)
df['page'] = df['keys'].apply(lambda x: x[1] if isinstance(x, list) and len(x) > 1 else None)
df = df.drop('keys', axis=1)
except Exception as e:
print(f"Warning: Could not split 'keys' column for {data_date}: {e}")
metric_cols = ['clicks', 'impressions', 'ctr', 'position']
for col in metric_cols:
if col in df.columns:
df[col] = pd.to_numeric(df[col], errors='coerce')
# else: # No need to print this repeatedly if a metric is consistently missing
# print(f"Note: Metric column '{col}' not found for {data_date}.")
if 'ctr' in df.columns:
df['ctr'] = df['ctr'] * 100
# Don't print success here, wait until after combining DFs if needed
# print(f"✓ Processed data for {data_date} into DataFrame ({len(df)} rows).")
return df
def get_gsc_data_for_day(service, site_url, data_date):
"""Fetches GSC data for a specific day, using cache if available."""
date_str = data_date.strftime('%Y-%m-%d')
cache_filename = os.path.join(CACHE_DIR, f"gsc_data_{date_str}.csv")
if os.path.exists(cache_filename):
try:
print(f"📂 CACHE: Loading data for {date_str} from cache: {cache_filename}")
df = pd.read_csv(cache_filename, dtype={
'clicks': 'Int64', 'impressions': 'Int64', 'ctr': 'float64',
'position': 'float64', 'query': 'object', 'page': 'object'
}, parse_dates=False)
if 'ctr' in df.columns and not df['ctr'].empty and df['ctr'].max() <= 1.0:
df['ctr'] = df['ctr'] * 100
return df
except Exception as e:
print(f"⚠️ Warning: Could not load cache file {cache_filename}. Error: {e}. Re-fetching.")
print(f"🔄 API: Fetching data for {date_str} from GSC API...")
request = {
'startDate': date_str, 'endDate': date_str,
'dimensions': ['query', 'page'],
'rowLimit': 25000, 'startRow': 0
}
raw_data = fetch_all_gsc_data(service, site_url, request)
df = process_gsc_data_to_dataframe(raw_data, date_str)
if not df.empty:
try:
os.makedirs(CACHE_DIR, exist_ok=True)
df.to_csv(cache_filename, index=False)
print(f"💾 Saved data for {date_str} to cache: {cache_filename}")
except Exception as e:
print(f"⚠️ Warning: Could not save data for {date_str} to cache. Error: {e}")
return df
# --- New Function for Trend Analysis ---
def analyze_trends(daily_dataframes_dict):
"""
Combines daily DataFrames and calculates trend slopes and time series.
Args:
daily_dataframes_dict (dict): Dict mapping date obj to daily GSC DataFrame.
Returns:
pandas.DataFrame: DataFrame with page, query, slopes, and time series lists.
Returns empty DataFrame if input is invalid or processing fails.
"""
if not daily_dataframes_dict or len(daily_dataframes_dict) < 2:
print("Error: Need at least 2 days of data for trend analysis.")
return pd.DataFrame()
# Get sorted dates from the dictionary keys
dates = sorted(daily_dataframes_dict.keys())
num_days = len(dates)
# Prepare list of dataframes to concatenate, adding date column
dfs_to_concat = []
for date, df in daily_dataframes_dict.items():
if not df.empty:
df_copy = df.copy() # Work on a copy
df_copy['date'] = pd.to_datetime(date) # Ensure date is datetime object
dfs_to_concat.append(df_copy)
if not dfs_to_concat:
print("Error: No valid DataFrames found to combine for trend analysis.")
return pd.DataFrame()
# Combine DataFrames
combined_df = pd.concat(dfs_to_concat, ignore_index=True)
print(f"\n✓ Combined data for {len(dates)} days into a single DataFrame ({len(combined_df)} rows total).")
# Add Day Index for regression
date_to_index = {pd.to_datetime(date): i for i, date in enumerate(dates)}
combined_df['day_index'] = combined_df['date'].map(date_to_index)
# Define metrics for trend analysis
metrics = ['impressions', 'clicks', 'position']
# --- Inner function to process each page/query group ---
def analyze_single_group(group):
# Convert the groupby result to a DataFrame if it's a Series
if isinstance(group, pd.Series):
group = group.to_frame().T
# Ensure date is in datetime format
if 'date' in group.columns:
group['date'] = pd.to_datetime(group['date'])
group = group.set_index('date')
# Create a complete date range
full_date_index = pd.to_datetime(dates)
# Create empty results dictionary
results = {}
# Handle each metric
for metric in metrics:
# Default values in case metric is missing
results[f'{metric}_ts'] = [0] * num_days # Default time series
results[f'{metric}_slope'] = np.nan # Default slope
# Skip processing if metric is not in the group's columns
if metric not in group.columns:
continue
# Get metric values for each date (align with date index)
metric_by_date = {}
for _, row in group.reset_index().iterrows():
if 'date' in row and pd.notnull(row['date']) and metric in row and pd.notnull(row[metric]):
dt = pd.to_datetime(row['date'])
metric_by_date[dt] = row[metric]
# Create time series array aligned with full date range
ts_values = []
for dt in full_date_index:
if dt in metric_by_date:
value = metric_by_date[dt]
# Handle impressions and clicks as integers (filled with 0)
if metric in ['impressions', 'clicks']:
ts_values.append(int(value) if pd.notnull(value) else 0)
# Handle position as float (can be NaN)
else:
ts_values.append(round(float(value), 1) if pd.notnull(value) else np.nan)
else:
# For missing dates: 0 for counts, NaN for position
ts_values.append(0 if metric in ['impressions', 'clicks'] else np.nan)
results[f'{metric}_ts'] = ts_values
# Calculate regression slope if we have enough valid data points
x = np.arange(num_days)
y = np.array(ts_values)
valid_mask = ~np.isnan(y)
valid_count = np.sum(valid_mask)
if valid_count >= 2: # Need at least two points for regression
try:
# Extract valid x and y values
x_valid = x[valid_mask]
y_valid = y[valid_mask]
# Calculate slope using numpy's polyfit
coeffs = np.polyfit(x_valid, y_valid, 1)
results[f'{metric}_slope'] = coeffs[0]
except (np.linalg.LinAlgError, ValueError, TypeError) as e:
# Handle computation errors
print(f"Warning: Slope calculation error for metric {metric}: {e}")
results[f'{metric}_slope'] = np.nan
return pd.Series(results)
# --- End of inner function ---
print("✓ Starting trend analysis by grouping page/query combinations...")
# Apply the analysis function to each group
# Handle potential errors during apply (e.g., unexpected data types)
try:
# Using include_groups=False to avoid deprecation warning
analysis_results = combined_df.groupby(['page', 'query'], observed=True, dropna=False).apply(
analyze_single_group, include_groups=False).reset_index()
print(f"✓ Trend analysis complete. Found {len(analysis_results)} unique page/query combinations.")
except Exception as e:
print(f"Error during groupby/apply operation for trend analysis: {e}")
return pd.DataFrame() # Return empty DF on error
# Optional: Round slopes for cleaner display
for metric in metrics:
col_name = f'{metric}_slope'
if col_name in analysis_results.columns:
analysis_results[col_name] = analysis_results[col_name].round(2)
return analysis_results
# --- Modify the main() function ---
def main():
"""Main execution function."""
# 1. Authenticate
gsc_service = authenticate_gsc()
# 2. Find most recent date
latest_date = find_most_recent_gsc_data_date(gsc_service, SITE_URL)
if not latest_date:
print("\nCannot proceed without a valid recent date.")
sys.exit(1)
print(f"\nSuccess: Most recent GSC data available is for: {latest_date.strftime('%Y-%m-%d')}")
# 3. Determine dates to fetch
dates_to_fetch = [latest_date - timedelta(days=i) for i in range(NUM_DAYS_TO_FETCH)][::-1]
print(f"\nPreparing to fetch/load data for {NUM_DAYS_TO_FETCH} days:")
print(f" Dates: {[d.strftime('%Y-%m-%d') for d in dates_to_fetch]}")
# 4. Fetch/load daily data
daily_dataframes = {}
api_calls_made = 0
cache_loads_made = 0
all_data_loaded = True
for target_date in dates_to_fetch:
date_str = target_date.strftime('%Y-%m-%d')
cache_filename = os.path.join(CACHE_DIR, f"gsc_data_{date_str}.csv")
cache_exists = os.path.exists(cache_filename)
df_day = get_gsc_data_for_day(gsc_service, SITE_URL, target_date)
# Track which source was used
if cache_exists and not df_day.empty:
cache_loads_made += 1
elif not df_day.empty:
api_calls_made += 1
# Even if df_day is empty, store it to represent the day
daily_dataframes[target_date] = df_day
# Check if loading/fetching failed *and* cache doesn't exist
if df_day.empty and not cache_exists:
print(f"⚠️ Warning: Data could not be fetched or loaded for {date_str}. Trend analysis might be incomplete.")
all_data_loaded = False
if not all_data_loaded:
print("\n⚠️ Warning: Data loading was incomplete. Proceeding with available data.")
print(f"\n📊 Data source summary: {cache_loads_made} days loaded from cache, {api_calls_made} days fetched from API")
# --- ADD TREND ANALYSIS STEP ---
# 5. Perform Trend Analysis
trend_results_df = analyze_trends(daily_dataframes)
# 6. Display Trend Analysis Results
if not trend_results_df.empty:
# Configure pandas display settings for better table formatting
pd.set_option('display.max_rows', 30)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', None)
pd.set_option('display.expand_frame_repr', False)
pd.set_option('display.max_colwidth', None)
# Create a simplified display dataframe with cleaner formatting
display_df = trend_results_df.copy()
# Process the dataframe for display
# 1. Extract page path from full URL
if 'page' in display_df.columns:
display_df['page'] = display_df['page'].str.replace(r'https://mikelev.in/futureproof/', '', regex=True)
# Further trim endings
display_df['page'] = display_df['page'].str.replace(r'/$', '', regex=True)
# 2. Convert time series lists to more compact string representations
for col in ['impressions_ts', 'clicks_ts', 'position_ts']:
if col in display_df.columns:
# Format time series values more compactly
display_df[col] = display_df[col].apply(
lambda x: '[' + ','.join([str(int(i)) if isinstance(i, (int, float)) and not pd.isna(i) else '-' for i in x]) + ']'
)
# 3. Format slope values to 1 decimal place
for col in ['impressions_slope', 'clicks_slope', 'position_slope']:
if col in display_df.columns:
display_df[col] = display_df[col].apply(
lambda x: f"{x:.1f}" if pd.notnull(x) else "-"
)
print("\n--- Top 15 by Impression Increase ---")
top_impressions = display_df.sort_values('impressions_slope', ascending=False, na_position='last').head(15)
print(top_impressions.to_string(index=False))
print("\n--- Top 15 by Position Improvement (Lower is Better) ---")
# Ensure we're working with original numeric values for sorting
numeric_df = trend_results_df.copy()
numeric_df = numeric_df.dropna(subset=['position_slope'])
# Sort by position_slope (lowest/most negative is best improvement)
top_positions_idx = numeric_df.sort_values('position_slope', ascending=True).head(15).index
# Display using the formatted display dataframe
print(display_df.loc[top_positions_idx].to_string(index=False))
# --- ADD NEW SECTION: Top Performers by Combined Score ---
print("\n--- Top 15 High-Impact Queries (Best Position + Most Impressions) ---")
# Get the most recent day in each time series
latest_data_df = trend_results_df.copy()
# Extract the most recent values from the time series lists
def get_latest_nonzero_value(ts_list, default=None):
"""Get the latest non-zero (or non-nan) value in a time series list."""
if not isinstance(ts_list, list):
return default
for value in reversed(ts_list): # Start from the most recent
if isinstance(value, (int, float)) and not pd.isna(value) and value > 0:
return value
return default
latest_data_df['latest_position'] = latest_data_df['position_ts'].apply(
lambda x: get_latest_nonzero_value(x, default=100)
)
latest_data_df['latest_impressions'] = latest_data_df['impressions_ts'].apply(
lambda x: get_latest_nonzero_value(x, default=0)
)
# Calculate combined score: impressions / position (higher score is better)
# This prioritizes high impressions and low positions
latest_data_df['impact_score'] = latest_data_df.apply(
lambda row: row['latest_impressions'] / max(row['latest_position'], 0.1)
if pd.notnull(row['latest_position']) and row['latest_position'] > 0
else 0,
axis=1
)
# Sort by the combined score and get top 15
top_impact_idx = latest_data_df.sort_values('impact_score', ascending=False).head(15).index
# Add the score to the display dataframe
display_df['latest_position'] = latest_data_df['latest_position'].round(1)
display_df['latest_impressions'] = latest_data_df['latest_impressions'].astype(int)
display_df['impact_score'] = latest_data_df['impact_score'].round(1)
# Truncate long queries for display
def truncate_query(query, max_length=50):
"""Truncate query string if longer than max_length."""
if len(query) <= max_length:
return query
return query[:max_length-3] + "..."
# Create a display version with truncated queries
display_df_truncated = display_df.copy()
display_df_truncated['query'] = display_df_truncated['query'].apply(truncate_query)
# Display the top impact queries with truncated query text
print(display_df_truncated.loc[top_impact_idx][['page', 'query', 'latest_position', 'latest_impressions', 'impact_score', 'impressions_ts', 'position_ts']].to_string(index=False))
print("\n--- DataFrame Info ---")
trend_results_df.info()
# Save the final trend analysis results using the original dataframe (with full URLs)
final_output_filename = os.path.join(SCRIPT_DIR, f"gsc_trend_analysis_{dates_to_fetch[0].strftime('%Y%m%d')}_to_{dates_to_fetch[-1].strftime('%Y%m%d')}.csv")
try:
trend_results_df.to_csv(final_output_filename, index=False)
print(f"\n✓ Saved final trend analysis to: {final_output_filename}")
except Exception as e:
print(f"\nWarning: Failed to save final trend analysis results. Error: {e}")
else:
print("\nTrend analysis could not be completed.")
print("\nScript finished.")
if __name__ == "__main__":
if not SITE_URL or SITE_URL == "sc-domain:yourdomain.com":
print("Error: Please update the 'SITE_URL' variable in the script configuration.")
sys.exit(1)
main()
Here’s how it works:
- Combine and Prepare: The
analyze_trendsfunction first concatenates the individual daily DataFrames into one largecombined_df. Crucially, it adds adatecolumn during this process and then calculates a numericalday_index(0, 1, 2, 3) representing the time sequence, which is necessary for the regression calculation. - Group and Analyze: The script then groups this combined data by each unique
pageandquerycombination. For every group, it performs the following:- Time Alignment: It ensures data for all 4 days is represented using
reindex, filling any missing days for a specific page/query pair withNaN(Not a Number). This is vital for comparing trends apples-to-apples. - Time Series Extraction: It stores the sequence of impressions, clicks, and position values over the 4 days into lists (e.g.,
impressions_ts). These are ready for potential sparkline visualization later. Missing values for impressions/clicks are treated as 0, while missing positions remainNaN. - Slope Calculation: Using
numpy.polyfit, it calculates the linear regression slope for impressions, clicks, and position against the day index. This slope value quantifies the trend (e.g., a positive impression slope means impressions are trending up). The calculation only proceeds if at least two data points are available for a given metric within the 4-day window; otherwise, the slope isNaN.
- Time Alignment: It ensures data for all 4 days is represented using
- Identify Top Movers: The script analyzes the calculated slopes to surface interesting changes:
- Impression Increase: It sorts the results by
impressions_slopein descending order to find page/query combinations gaining the most visibility. - Position Improvement: It sorts by
position_slopein ascending order (most negative slope first) to find combinations whose average ranking improved the most significantly. - High Impact: Recognizing that trends are only part of the story, it adds a crucial third view. It looks at the most recent day’s data for each page/query pair, calculates an
impact_score(latest impressions divided by latest position), and sorts by this score. This surfaces queries that are currently driving significant impressions from good ranking positions, regardless of the short-term trend.
- Impression Increase: It sorts the results by
- Format and Save:
- For clearer console output, the script formats the results: page URLs are shortened, time-series lists are displayed compactly (e.g.,
[10, 15, 20, 27]), and slopes are shown with a sign (+/-) and one decimal place. - The raw, unformatted results of the trend analysis (including the full page URLs, slopes, and time-series lists) are saved to a CSV file named with the date range (e.g.,
gsc_trend_analysis_20250405_to_20250408.csv). This allows for more in-depth analysis or visualization later.
- For clearer console output, the script formats the results: page URLs are shortened, time-series lists are displayed compactly (e.g.,
- Caching Mention: Throughout the process, the script leverages the caching mechanism established earlier, loading daily data from local CSV files when available to minimize redundant API calls and speed up execution on subsequent runs. It also reports how many days were loaded from cache versus fetched live.
This comprehensive analysis provides multiple angles to understand recent performance shifts – identifying rapidly growing terms, ranking improvements, and currently impactful queries – giving actionable insights for SEO efforts.
Running The Trend Analysis Script
Executing this final script performs the entire process: authentication, finding the latest date, fetching/caching 4 days of data, combining the data, calculating trend slopes, and finally displaying the top “movers and shakers” based on impression gains and position improvements.
Here’s an example of what the formatted output might look like (data will vary):
[mike@nixos:~/repos/pipulate/precursors]$ python gsc_top_movers.py
✓ Successfully authenticated with Google Search Console API.
Finding most recent data date for site: sc-domain:mikelev.in
Starting check from date: 2025-04-09
Checking date 2025-04-09... ✓ Data found!
Success: Most recent GSC data available is for: 2025-04-09
Preparing to fetch/load data for 4 days:
Dates: ['2025-04-06', '2025-04-07', '2025-04-08', '2025-04-09']
📂 CACHE: Loading data for 2025-04-06 from cache: /home/mike/repos/pipulate/precursors/gsc_cache/gsc_data_2025-04-06.csv
📂 CACHE: Loading data for 2025-04-07 from cache: /home/mike/repos/pipulate/precursors/gsc_cache/gsc_data_2025-04-07.csv
📂 CACHE: Loading data for 2025-04-08 from cache: /home/mike/repos/pipulate/precursors/gsc_cache/gsc_data_2025-04-08.csv
📂 CACHE: Loading data for 2025-04-09 from cache: /home/mike/repos/pipulate/precursors/gsc_cache/gsc_data_2025-04-09.csv
📊 Data source summary: 4 days loaded from cache, 0 days fetched from API
✓ Combined data for 4 days into a single DataFrame (7591 rows total).
✓ Starting trend analysis by grouping page/query combinations...
✓ Trend analysis complete. Found 6499 unique page/query combinations.
--- Top 15 by Impression Increase ---
page query impressions_ts impressions_slope clicks_ts clicks_slope position_ts position_slope
grok-better-than seo recommendations [0,0,0,31] 9.3 [0,0,0,0] 0.0 [-,-,-,99] -
ai-agentic-mode-debugging git cherry pick [0,0,21,20] 8.1 [0,0,0,0] 0.0 [-,-,75,70] -4.7
grok-better-than seo concepts [0,0,0,27] 8.1 [0,0,0,0] 0.0 [-,-,-,82] -
grok-better-than htmx [0,0,0,24] 7.2 [0,0,0,0] 0.0 [-,-,-,70] -
static-site-generator-ai-content-strategy seo methodology [0,0,32,11] 6.5 [0,0,0,0] 0.0 [-,-,92,96] 3.9
grok-better-than git cherry pick [0,0,0,21] 6.3 [0,0,0,0] 0.0 [-,-,-,84] -
grok-better-than python seo [0,0,0,21] 6.3 [0,0,0,0] 0.0 [-,-,-,80] -
ai-agentic-mode-debugging cursor ai [0,0,27,11] 6.0 [0,0,1,0] 0.1 [-,-,41,43] 1.5
static-site-generator-ai-content-strategy striking distance keywords [0,0,26,11] 5.9 [0,0,0,0] 0.0 [-,-,63,64] 0.7
grok-better-than google keyword planner tool [0,0,0,19] 5.7 [0,0,0,0] 0.0 [-,-,-,77] -
static-site-generator-ai-content-strategy git cherry pick [0,0,21,12] 5.7 [0,0,0,0] 0.0 [-,-,91,89] -2.6
static-site-generator-ai-content-strategy python for seo [0,0,44,4] 5.6 [0,0,0,0] 0.0 [-,-,95,96] 0.9
grok-better-than guide to seo [0,0,0,18] 5.4 [0,0,0,0] 0.0 [-,-,-,98] -
ai-agentic-mode-debugging git revert [0,0,17,12] 5.3 [0,0,0,0] 0.0 [-,-,72,75] 3.1
grok-better-than seo explanation [0,0,0,17] 5.1 [0,0,0,0] 0.0 [-,-,-,96] -
--- Top 15 by Position Improvement (Lower is Better) ---
page query impressions_ts impressions_slope clicks_ts clicks_slope position_ts position_slope
llm-seo-software-development webassembly dom [0,1,1,0] 0.0 [0,0,0,0] 0.0 [-,124,70,-] -54.0
llm-seo-software-development cheek holes [0,1,1,0] 0.0 [0,0,0,0] 0.0 [-,97,69,-] -28.0
static-site-generator-ai-content-strategy wordpress metadata [0,0,2,1] 0.5 [0,0,0,0] 0.0 [-,-,96,68] -28.0
ai-agentic-mode-debugging how to fix my beats [0,0,1,1] 0.4 [0,0,0,0] 0.0 [-,-,95,72] -23.0
cursor-ai-terminal-agent-mode squashfs [0,1,1,0] 0.0 [0,0,0,0] 0.0 [-,115,95,-] -20.0
from-blog-to-book-ai-powered-ia jupyter lite [0,0,1,1] 0.4 [0,0,0,0] 0.0 [-,-,76,56] -20.0
ai-agentic-mode-debugging hamster wheel [0,0,20,2] 2.6 [0,0,0,0] 0.0 [-,-,76,57] -19.2
ai-agentic-mode-debugging compare two branches git [0,0,2,1] 0.5 [0,0,0,0] 0.0 [-,-,99,81] -18.5
from-blog-to-book-ai-powered-ia chunking strategies for rag [0,0,1,1] 0.4 [0,0,0,0] 0.0 [-,-,90,72] -18.0
vscode-jupyter-notebook-paths does cursor work with jupyter notebook [1,1,0,0] -0.4 [0,0,0,0] 0.0 [29,11,-,-] -18.0
ai-agentic-mode-debugging git revert changes to file [0,0,1,2] 0.7 [0,0,0,0] 0.0 [-,-,97,79] -18.0
from-blog-to-book-ai-powered-ia prolimit [0,0,3,1] 0.6 [0,0,0,0] 0.0 [-,-,81,64] -17.7
ai-agentic-mode-debugging github pipeline [0,0,2,1] 0.5 [0,0,0,0] 0.0 [-,-,88,71] -17.5
llm-seo-software-development open webui [0,4,2,0] -0.2 [0,0,0,0] 0.0 [-,78,61,-] -17.3
static-site-generator-ai-content-strategy parse yaml [0,0,1,1] 0.4 [0,0,0,0] 0.0 [-,-,101,85] -16.0
--- Top 15 High-Impact Queries (Best Position + Most Impressions) ---
page query latest_position latest_impressions impact_score impressions_ts position_ts
grok3-markdown-problem grok was unable to finish replying. please try ... 7.8 19 2.4 [26,9,12,19] [7,7,8,7]
jupyter-notebook-vscode-cursor cursor ai jupyter notebook 6.7 12 1.8 [9,4,5,12] [6,7,6,6]
grok3-markdown-problem grok glitch 6.9 12 1.7 [3,7,12,12] [3,5,5,6]
mcp-with-local-llm local llm mcp 6.1 8 1.3 [4,8,0,0] [6,6,-,-]
open-source-seo-software seo software linux 21.7 25 1.2 [5,47,9,25] [20,22,23,21]
grok3-markdown-problem grok was unable to finish replying 8.7 10 1.1 [4,2,1,10] [8,9,9,8]
grok3-markdown-problem grok markdown 2.7 3 1.1 [3,4,3,3] [3,1,1,2]
https://mikelev.in michael levin blog 3.8 4 1.1 [3,1,2,4] [4,4,3,3]
grok3-markdown-problem grok was unable to finish replying. 8.8 9 1.0 [7,12,5,9] [7,7,7,8]
grok-better-than entity you are doing the search for: {"name": "... 2.0 2 1.0 [0,0,0,2] [-,-,-,2]
nixos-warbler-files-disappeared nixos warbler 1.0 1 1.0 [1,1,0,0] [1,1,-,-]
grok3-markdown-problem grok problems 1.0 1 1.0 [1,0,0,1] [9,-,-,1]
peak-data-musk-sutskever-wrong peak data theory 1.0 1 1.0 [2,0,1,1] [5,-,3,1]
grok3-markdown-problem grok 3 prompt limit 1.0 1 1.0 [0,0,0,1] [-,-,-,1]
jupyter-notebook-vscode-cursor cursor jupyter notebook 6.2 6 1.0 [12,9,9,6] [9,8,11,6]
--- DataFrame Info ---
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6499 entries, 0 to 6498
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 page 6499 non-null object
1 query 6499 non-null object
2 impressions_ts 6499 non-null object
3 impressions_slope 6499 non-null float64
4 clicks_ts 6499 non-null object
5 clicks_slope 6499 non-null float64
6 position_ts 6499 non-null object
7 position_slope 914 non-null float64
dtypes: float64(3), object(5)
memory usage: 406.3+ KB
✓ Saved final trend analysis to: /home/mike/repos/pipulate/precursors/gsc_trend_analysis_20250406_to_20250409.csv
Script finished.
This provides a powerful, automated way to monitor recent performance changes and identify potential content optimization opportunities directly from your GSC data. The final CSV contains all the calculated data for further analysis or visualization.
Voila! Sparklines
Do I really have to draw the sparklines for you? The data’s ready to bring into Excel or whatever. If you’re in a web app environment, there are plenty of libraries that can take these little 4-point arrays and draw you sparklines. A sign of good data preparation is the text representation is so good, you hardly have to visualize. The visualization component merits a whole other article, so I will assume anyone interested in an article like this who got down this far can glance at those above numbers and “get it”. There are your movers and shakers there at the top of the lists plain as day.
The site suddenly went from not being in search at all to suddenly having positions, terrible as those positions may be. If you’re actually here on my site reading this, may I suggest playing with that page-width slider to be able to see the maximum number of columns available in those tables without horizontal scrolling. Things like average position are all the way over on the right, so while you may see keywords suddenly having impressions, to get the full story, you want to see what average positions in search they were in on those impressions.
Your site impression traffic may surge just because you wander into the space of “monitored” keywords by tools like SEMRush and stuff. I mean, who’s going to page 10 of search results? Now that you need to “render” search results with a web browser (scraping SERPs isn’t as easy as it used to be), bots are going to look more like genuine impressions. So my surge could just be bots monitoring SERPs, especially on terms like “seo software”. But you’ve got to be found at all before you can dominate. So, it’s a start.
And Here’s a Prompt for AI to Help Analyze Data
Analyze the Google Search Console trend analysis output previously provided for the site sc-domain:mikelev.in (covering the period April 7-10, 2025). Based only on that data, provide a prioritized list of actionable traffic growth suggestions.
Your goal is to identify the highest-impact opportunities revealed by the trends, including both broad strategic directions and specific content pieces. Structure your response to cover the following areas, ensuring each point includes specific examples from the data (pages, queries, metrics) and concrete recommended actions:
1. Top Movers Opportunities:
* Identify the most promising opportunities among pages/queries showing strong positive impression growth.
* Specifically highlight queries gaining significant impressions and improving in position simultaneously.
* Recommend specific actions (e.g., optimize page X for query Y, expand content on topic Z) to capitalize on this momentum.
2. Position Improvement Momentum:
* Which pages making significant ranking jumps (large negative position_slope) represent the best targets for further optimization to secure or improve those gains?
* Are there thematic patterns among the fastest climbers that suggest broader content opportunities?
* Recommend actions to consolidate these ranking improvements.
3. High-Impact & Unrealized Potential Optimization:
* Based on the “High-Impact Queries” list, which content currently delivers the most value and how can it be reinforced or expanded?
* Identify the top 1-3 individual page/query pairs representing the largest “unrealized potential” (high impressions but poor ranking). Clearly state the page, query, impressions, and position for these top examples.
* Critically, based specifically on analyzing this unrealized potential data, identify and recommend the single most promising new article topic to pursue to capture this untapped traffic. Justify why this specific topic is the best choice over other unrealized potential candidates.
* Recommend specific optimization strategies for these high-potential items (e.g., create the new targeted article, significantly enhance/rewrite existing page, technical SEO review, consolidate competing pages).
4. Prioritized Strategic Recommendations:
* Synthesize the findings from the above points.
* What are the top 2-3 overarching strategic priorities? Ensure these recommendations explicitly cover both broad themes (like refining generalist pages such as grok-better-than, or amplifying existing winners like open-source-seo-software) AND the specific, standout individual topic opportunity (like the best new article topic identified in point 3). Justify these priorities with data trends.
Please ensure recommendations are concrete and directly linked to the patterns observed in the provided GSC trend data output.
Gemini 2.5:
Okay, here is an analysis of the Google Search Console trend data for sc-domain:mikelev.in (covering April 7-10, 2025) with prioritized, actionable traffic growth suggestions based only on the provided data.
1. Top Movers Opportunities:
- Observation: The page
grok-better-thanis showing significant positive impression growth (impressions_slope) for several distinct query clusters: SEO tools (e.g., “google keyword planner”, “keyword planner tool”), technical SEO concepts (“python for seo”, “seo for beginners”, “seo concepts”), and Git commands (“git cherry pick”). - Highest Promise (Impression Growth + Position Improvement): Several queries for
grok-better-thanshow both strong positiveimpressions_slopeand negativeposition_slope(ranking improvement):- “google keyword planner”:
impressions_slope9.2,position_slope-1.2 (Pos ~79) - “python for seo”:
impressions_slope8.3,position_slope-2.4 (Pos ~82) - “git cherry pick”:
impressions_slope6.6,position_slope-2.6 (Pos ~82) - “seo for beginners”:
impressions_slope4.6,position_slope-4.9 (Pos ~93)
- “google keyword planner”:
- Recommendations:
- Action: Prioritize optimizing the
grok-better-thanpage. Enhance its content to specifically and comprehensively address “google keyword planner”, “python for seo”, “git cherry pick”, and “seo for beginners”. Use these terms in headings (H2s, H3s) and body content. - Action: Improve internal linking to the
grok-better-thanpage from other relevant site content using anchor text related to these growing queries (e.g., link from a Git tutorial using “git cherry pick”, link from an SEO overview using “python for seo”). - Action: Although “keyword planner tool” (
impressions_slope8.2) saw its position slightly worsen (position_slope0.2, Pos ~86), the high impression growth warrants ensuring this specific phrasing is also well-integrated into thegrok-better-thanpage.
- Action: Prioritize optimizing the
2. Position Improvement Momentum:
- Observation: Several pages show significant ranking jumps (large negative
position_slope). The most dramatic jumps often have low initial impression volume, but consistent themes emerge among moderate-to-strong climbers. - Best Targets & Thematic Patterns:
- Git Commands: Pages
ai-agentic-mode-debuggingandgrok-better-thanare seeing ranking improvements for various Git queries like “compare two branches git” (-18.5), “git revert changes to file” (-18.0), “git reset –hard head” (-12.3 forgrok-better-than), etc. This indicates a growing relevance or successful optimization push for Git-related content. - Python/Jupyter: The
grok-better-thanpage is also climbing for queries like “stream python” (-24.0, Pos ~65) and “jupyter project” (-23.0, Pos ~75). - Specific Tools/Platforms:
open-source-seo-softwareis making steady gains for specific queries like “seo tool open source” (-10.0, Pos ~21) and “open source seo toolkit” (-9.2, Pos ~24).
- Git Commands: Pages
- Recommendations:
- Action: Consolidate gains for Git content. Review
ai-agentic-mode-debuggingandgrok-better-thanto ensure comprehensive coverage, clear explanations, and practical examples for the improving Git queries (diff, revert, reset, cherry-pick). Add internal links between these specific command explanations. - Action: Reinforce the improving Python/Jupyter rankings on
grok-better-than. Add more code examples, use cases, or clarify explanations for “stream python” and “jupyter project”. - Action: Solidify the improved rankings for
open-source-seo-softwareby updating the tool list, adding more detailed reviews/comparisons, or improving the page structure for queries like “seo tool open source” and “open source seo toolkit”.
- Action: Consolidate gains for Git content. Review
3. High-Impact & Unrealized Potential Optimization:
- Current High-Impact Content:
grok-better-thanfor “entity you are doing the search for: …” (Pos 2.0, Imp 11) - Likely navigational, maintain page quality.jupyter-notebook-vscode-cursorfor “cursor ai jupyter notebook” (Pos 5.3, Imp 10) - Delivers value.grok3-markdown-problemfor “grok was unable to finish replying.” (Pos 7.7, Imp 11) - Strong performance for a specific problem.open-source-seo-softwarefor “open source seo software” (Pos 16.6, Imp 19) - High impact despite weaker rank, significant potential.
- Top 1-3 Unrealized Potential (High Impressions, Poor Rank):
- Page:
static-site-generator-ai-content-strategy, Query: “seo techniques”, Latest Impressions: 64, Latest Position: 93.1 - Page:
llm-seo-software-development, Query: “python for seo”, Latest Impressions: 42, Latest Position: 81.0 - Page:
github-pages-blog-arrows, Query: “github pages”, Latest Impressions: 27, Latest Position: 48.3
- Page:
- Single Most Promising New Article Topic:
- Topic: SEO Techniques
- Justification: The query “seo techniques” shows the highest impression volume (64) among all identified high-potential opportunities where the site currently ranks very poorly (Pos 93.1). This indicates strong audience demand for this topic that the site isn’t currently meeting effectively with existing content (the page ranking,
static-site-generator-ai-content-strategy, is likely too niche or unfocused for such a broad query). Creating a dedicated, comprehensive article specifically targeting “SEO Techniques” represents the single largest opportunity revealed by this data to capture significant untapped traffic. While “python for seo” also has high volume (42 impressions, Pos 81.0), “seo techniques” has ~50% more impressions, suggesting a larger potential audience reach.
- Recommendations:
- Action: Create a new, comprehensive, standalone article titled and focused on “A Guide to Modern SEO Techniques”. Structure it logically covering on-page, off-page, technical, local, etc. Link to this new pillar content from other relevant pages.
- Action: Significantly enhance
llm-seo-software-developmentto better target “python for seo” (add code examples, libraries, use cases) OR ensure it links prominently to thegrok-better-thanpage section covering this (if that page remains the primary target). - Action: Enhance
github-pages-blog-arrowsto be the definitive resource on the site for “github pages”, covering setup, SEO best practices, SSGs, etc. - Action: Reinforce
jupyter-notebook-vscode-cursorby adding more detail, visuals, or potentially a video tutorial for “cursor ai jupyter notebook”. Updateopen-source-seo-softwareregularly.
4. Prioritized Strategic Recommendations:
Based on the synthesis of the above points, the top 2-3 strategic priorities are:
- Create a Pillar Content Piece on “SEO Techniques”: This directly addresses the single largest identified “unrealized potential” opportunity (Query: “seo techniques”, Imp: 64, Pos: 93.1). Capturing even a fraction of this traffic by creating a dedicated, high-quality article could significantly boost overall site visibility and traffic. This is the highest-priority specific action derived from the data.
- Refine Broad Pages & Capitalize on Thematic Strengths (Dev Tools/SEO):
- Refine
grok-better-than: This page attracts high impression growth across diverse topics (SEO tools like “google keyword planner”, Git commands like “git cherry pick”, “python for seo”) but ranks poorly. Clarify its focus, improve structure, and ensure it deeply covers the high-volume queries it’s gaining traction for, potentially spinning off overly distinct topics into dedicated posts. - Amplify Tech/Dev Tool Winners: Reinforce successful pages like
jupyter-notebook-vscode-cursor(Pos 5.3 for its primary query) and high-potential ones likeopen-source-seo-software(Pos 16.6, Imp 19). Continue building out content around improving themes like Git, Python for SEO, NixOS, and HTMX where momentum is visible.
- Refine
Getting The Final, Final Code
These projects are living documents. I go back and I tweak and improve them over
time. Articles like this really only capture their state where I left off and
was motivated to wrap improvements back into the article. The final final state
may be somewhat beyond this. For example, I wrapped in that prompt to the
program itself, so I can copy/paste the output of the program directly into the
Web UI of a ChatBot to get the recommendations. If you want the latest latest
versions, check out the precursor folder in the pipulate repo in GitHub.
These types of things are all precursors to Pipulate apps.
Gemini 2.5’s Take
Okay, here is the analysis and generated outputs based only on the provided article text:
-
Author Summary:
- Title/Headline Ideas:
- Find Your SEO Movers & Shakers: GSC API Trend Analysis with Python
- Beyond 1000 Rows: Unlocking GSC Granularity with Python & Trend Slopes
- GSC API & Python: Step-by-Step Guide to Performance Trend Analysis
- Automating GSC Insight: Identify Keyword & Page Momentum with Python
- From Hockeystick to Action: Python GSC Analysis for SEO Opportunities
- Strengths:
- Practical How-To: Provides a clear, step-by-step guide with evolving code examples.
- Complete Code: Includes full Python scripts for authentication, data fetching, processing, and analysis.
- Addresses a Real Need: Solves the common GSC limitation of accessing granular, per-query/per-page data beyond UI limits.
- Specific Analysis Technique: Introduces a concrete method (linear regression slope) for identifying trends.
- Actionable Outcome: The process aims to surface actionable insights (“movers and shakers”, high-impact queries).
- Good Practice: Incorporates caching to avoid redundant API calls.
- Extensibility: Includes an AI prompt for further strategic analysis, adding practical value.
- Weaknesses:
- Complexity/Length: The code becomes quite extensive, potentially intimidating for less experienced Python users.
- Assumed Knowledge: Requires familiarity with Python, Pandas, Google Cloud Platform (GCP), and API authentication concepts (service accounts).
- Limited Interpretation: The article focuses heavily on the how (code) and defers deep strategic interpretation of the results, relying on the AI prompt for that.
- Linear Structure: The incremental build-up, while good for teaching, can make it hard to grasp the final script without reading everything.
- Readability: Multiple large code blocks showing incremental changes might impact overall readability compared to a single final script with explanations.
- AI Opinion: This is a high-quality, technically detailed article demonstrating a practical approach to advanced Google Search Console analysis using Python and the GSC API. Its strengths lie in the step-by-step code development, clear explanation of the need for API access, and the introduction of specific trend analysis techniques (linear regression slopes). The inclusion of working code, caching, and a final AI analysis prompt adds significant value. While potentially challenging for Python novices due to its length and complexity, it’s highly useful for technical SEOs seeking to automate granular performance monitoring and identify actionable opportunities beyond the standard GSC interface.