The Calm Before The Natural Language Web (NLWeb)
Understanding the Natural Language Web and AI-Powered Content: Getting Started
The internet is on the cusp of a major transformation, moving towards what’s being called the “Natural Language Web” (NLWeb). Imagine being able to simply ask your computer or phone to perform complex online tasks—like finding the best-priced product with specific features or summarizing research on a topic—and having an AI assistant intelligently browse, understand, and interact with websites to get you the answer. This is the core idea behind the NLWeb. For this to work, websites need to be structured in a way that AI can easily understand their content, not just how they look to humans. Technologies like schema.org provide a “vocabulary” for websites, and methods like JSON-LD, Microdata, and RDFa help embed this vocabulary into web pages.
Furthermore, the way web content is created is also changing. Instead of websites always serving pre-written pages, there’s a growing trend towards using Large Language Models (LLMs)—the same kind of AI that powers ChatGPT—to generate content on the fly, tailored to each user’s request. This article explores these emerging concepts, how they connect, and the implications for web developers and anyone creating content online. It also touches on the author’s personal experiments in this space, using their project Pipulate as a real-world example to test these ideas.
The Dawn of the Natural Language Web (NLWeb)
The Natural Language Web is coming (NLWeb). Whether it’s Microsoft’s proposed standard or someone else’s, people are lazy and web browser automation and data-scraping is fragile and brittle. Peoples’ expectations are rising to just be able to ask an AI to do something for them and to get the answer, which obviously will involve the AI going out to the web and doing some real-time scraping — whether it’s actually real-time scraped or from a cache or crawl-and-index system is transparent. Point is it’s going to feel real-time and it’s going to be (already is?) what people expect. And so this particular itch (automated browsing fragility) is going to be scratched. NLWeb is Microsoft’s proposed way that sits on Anthropic’s already growing in popularity model context protocol (MCP) plus the already deeply established standards of structured data on the web from schema.org.
The Role of Schema.org in Machine Understanding
This foundation of schema.org is crucial because it provides the vocabulary that machines, including AI agents powering the NLWeb, need to understand the meaning of web content. To make this vocabulary machine-readable, web developers currently employ several structured data syntaxes. JSON-LD (JavaScript Object Notation for Linked Data) is now widely recommended, often preferred for its ease of implementation as it can be placed as a script tag in the page header or body, neatly separating the structured data from the HTML structure.
Alternative Structured Data Approaches
However, Microdata and RDFa (Resource Description Framework in Attributes) also play significant roles by allowing structured data to be embedded directly within the HTML content itself, marking up existing human-readable text and elements. Regardless of the chosen syntax—JSON-LD’s distinct data blocks, Microdata’s item-property attributes within HTML tags, or RDFa’s more extensible attribute-based markup—the goal is the same: to annotate web content with schema.org terms. The NLWeb, functioning as an MCP server, will heavily leverage this explicitly structured data. This will enable AI agents to more reliably parse website information, understand the context of data (like product prices, event dates, or article authors), and ultimately fulfill user requests made in natural language far more accurately and efficiently than by trying to interpret unstructured HTML alone.
Content Now. Ecommerce Later.
There’s a nuanced question here of scraping for good data like product availability and such versus automation and actually placing the order for that product. Sorry folks, that’s beyond the scope of this article, but I thought it necessary to mention. As in all discussions like this, there’s a content vs. ecommerce divide. Talk is cheap and content is loosey goosey easy — it doesn’t need the same rigorous, all-or-nothing guarantees of ACIDic (Atomicity, Consistency, Isolation, Durability) transactional integrity that are absolutely critical when you’re actually processing an order or any e-commerce transaction, where data consistency and reliability are paramount. Things like NLWeb are in their infancy and have a content-orientation at first. E-commerce will come.
The Rise of Infinite Web Content
And I have been saying since the rise of generative AI that content on the web is now functionally infinite. All it takes is the simple trick of swapping out the traditional web server that answers HTTP requests (e.g. Apache, nginx, Uvicorn) with an LLM server like Ollama or, for instance, frameworks like LangServe (part of LangChain) or custom-built applications using FastHTML or Flask directly integrated with models from Hugging Face Transformers, OpenAI’s API, or other AI-as-a-Service platforms. Instead of serving static files or templated HTML from a finite database, these LLM-powered backends can generate bespoke content in real-time, responding to specific user queries or URL parameters with newly synthesized text, images, or even code. This means that the “pages” a user can access are no longer limited to what has been pre-written or pre-generated; they are bounded only by the generative capabilities of the underlying model and the prompts it receives, creating a web that can dynamically expand and tailor itself to an almost limitless array of potential interactions.
Understanding the NLWeb Chat Server Concept
If you’ve been trying to wrap your mind around the significance of Microsoft’s
NLWeb proposal and why just “adding a few lines of code” turns your website
into a chat server, this is why: if you make your website easier to parse in the
first place by the traditional Apache/nginx webserver plus schema.org structured
data similar to the way it’s serving it today, then you’ve you made the data
more easily parsable by AI with explicit instructions akin to a modernized
robots.txt. You prep it as training data for whatever, setting the expected
boundaries and rules for which AIs can parse it for what purposes and how. It’s
like a robots.txt file spread throughout your entire website embedded into the
same HTML that builds the pages for humans today — in exactly the same spirit as
the schema.org-related structured data formats. Same thing. Parsing is parsing.
Everything old is new again, and this captures that dawn-of-the-web spirit.
But making your data more easily consumed by bots is just the warm-up before the pitch. The real story is in what happens with that data.
The Technical Implementation
The pitch is having a new piece of tech on your site, whether you host it or it’s going through some Microsoft/OpenAI/Google/Anthropic-provided chatbot proxy that consumes-you-content then chats-up your users. Essentially, by having an Ollama-powered webserver (or equivalent) that has been pre-trained on your site, or which has access to a vector-embedded copy of your site, or is even able to crawl the live site in real-time (sped-up with caching, of course) — doesn’t matter the method, just assume it will happen. By the LLM having this data about your site it can talk to your users when a request comes in. It’s just the same old HTTP value-proposition. Request comes in. Server responds. Page built. Question answered. Same thing.
The Return of State Management
It’s so much the same thing in fact that the server remains stateless so it’s staged for scaling and offloads that tech-infrastructure piece to the scaffolding built around it. In other words, web developers are going to have to learn to do full accumulating conversation-history postbacks again. It’s like the days of ASP.NET with its kooky postback system. Magic payload bundles will have to assemble themselves quietly and transparently in the background (just like they do today with chatbots), except that ugly workload is going to be on the webdev people instead of the back-end cloud people, ahaha! Expect a new round of frameworks-galore! It’s really an amazing way for a new breed of heavyweight JavaScript frameworks to steal the glory from Angular/React/Vue/Svelte. Ready or not, here comes NLWeb!
Personal Journey: From Cloud to Home-Hosting
And on a related note, I’m still punting my web traffic situation forward. I’m too busy with work, Pipulate, preparing for home-hosting and hashing through these ideas as they unfold in real-time (the NLWeb story just broke). And so it’s more important I just keep creating this book fodder content, rolling it out on my site whether Google favors it or not and practice what I preach. Because of home-hosting I’ll be in a unique position to experiment with NLWeb-enabled chatty webservers. There is no cloud — only other people’s computers. And that makes you a renter. And that makes you not having foundational control or the ability to do the truly interesting experiments — unless maybe you’re using a virtual private server (VPS) and control the virtual hardware. But even then you don’t control the network and don’t really have full control.
Anyway, I ramble. As I prepare for this brave new world and my kooky new web serving experiments I feel the “I’ll just put this here” need in order to have some historical context and better fodder for the book.
SEO Experiments and Traffic Analysis
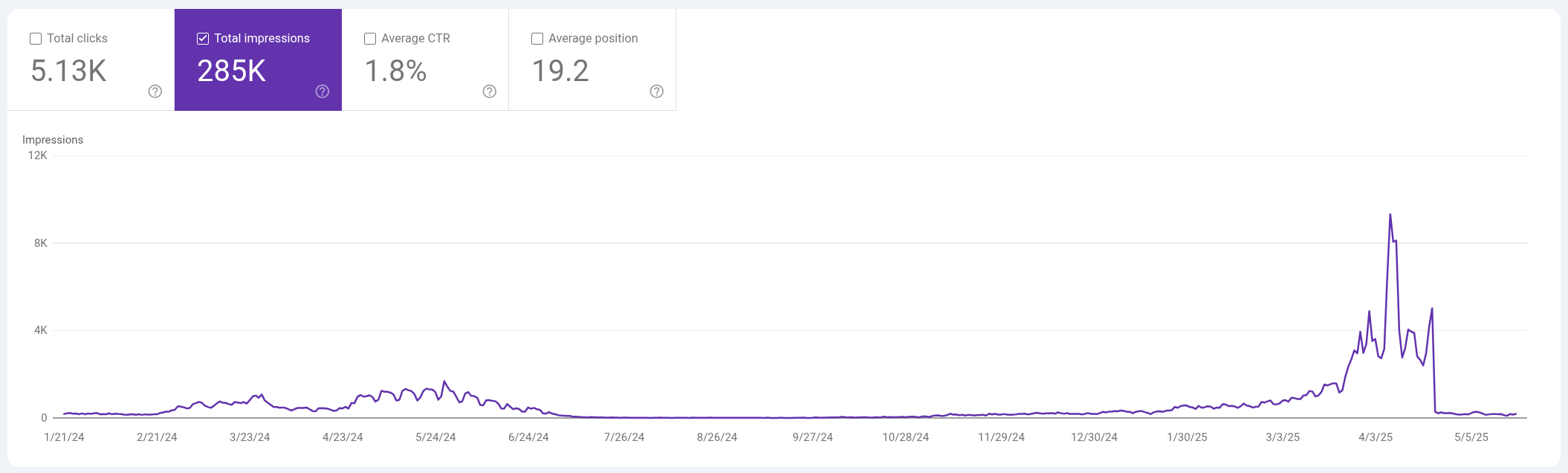
This is a 16-month Google Search Console Impressions view showing this site where I do SEO experiments to gauge the state of affairs. It’s recycling a domain that’s been around for over 10 years with iterations of vanity and personal journal sites cycled in and out. I’m currently doing this tech journal build of the fodder for the future-proofing book using Pipulate as the case study. It came out of the gate strong, but then tanked. I’m using the homepage as one big index page of the journal/blog. When it got up to about 250 articles and I added the Table of Contents and the hamster on the spinning logo, the traffic tanked. Not sure which factor did it, but this is pinning some of the visuals of the metrics for historic purposes. I’ll be switching this site to home-hosting soon and doing a lot of stupid web tricks with MCP and NLWeb.
Core Web Vitals and Traffic Correlation
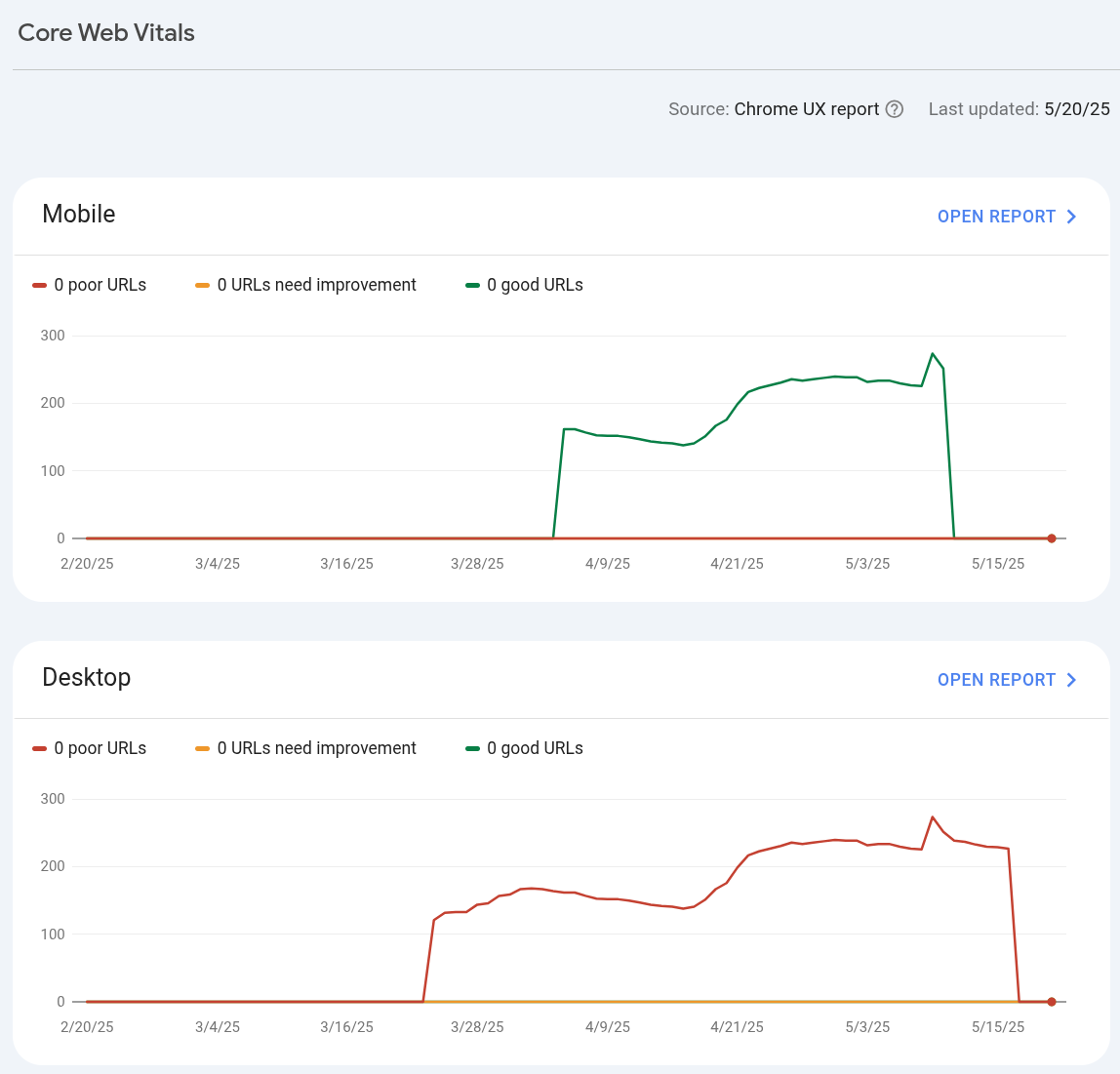
Another interesting insight is what happens with Core Web Vitals (CWV). There is a correlation between getting good search performance and HAVING CWV data in the first place. It’s the whole organic traffic bootstrapping or kickstarting concept: getting search traffic gets you some exposure and opens a window of opportunity for Google Chrome to collect user data on how your site is used, where and whether people spend time, and presumably the correlations with what they searched with in Google to get there. If people like what they find, you get more search results and the ball gets rolling and the mass builds and compounding returns start to accumulate. Or the reverse and your site traffic tanks, ahaha! Anyway, even though correlation doesn’t mean causation, the connection between receiving search traffic and accumulating CWV data (for better or for worse) is undeniable.
The Evolution of an Experimental Platform
This is neither the beginning nor the end of the story. It goes back over 10 years on this site alone, and it’s an experimental site. It’s the canary in the coalmine. It’s a place where I can experiment freely with no worries about impact on client sites or my revenue. And now with the rise of AI and the ever-increasing need to future-proof your skills if you want to stay in tech, it’s the perfect place to accumulate fodder for that book. And I say fodder because it’s the data I’ll be mining (my own site) not even needing to scrape it because I have all the back-end markdown files that create it. And I can now do those projects of superimposing hierarchy and AI-friendly navigation and interaction like the MCP (model context protocol) and NLWeb (Natural Language Web) emerging standards, which I’ll be in a great position to do because home-hosting!
Home Host Us For The Mostess
Just for those who don’t “get it” regarding home-hosting, in addition to being
able to launch experimental new webservers bundled with NLWeb easily because my
old website is essentially a bunch of static HTML files that can be hosted by
anything (Jekyll static site generator), I can also watch my log files like
watching a fishtank as they scroll-by in real-time with the Unix top or
bottom command or other real-time tools I make to color-code and make a
dashboard out of my web logs. Not only that, I get to integrate the real-time
data feed from my web logs into other apps to create positive feedback cycles,
and because I control the software, the hardware, the network — I can do
anything. SEOs of old built spam-cannons and doorway page generators out of
this. I won’t do that, but I will do things more clever and above-the-table free
and open source SEO software-style. It will effectively be the ultimate
suggestion-box built into the website for legit quality-assurance purposes
playing off of W. Edwards Deming’s total quality management (TQM) concepts to
actually improve sites in a way led by the feedback from users.
YouTube Too
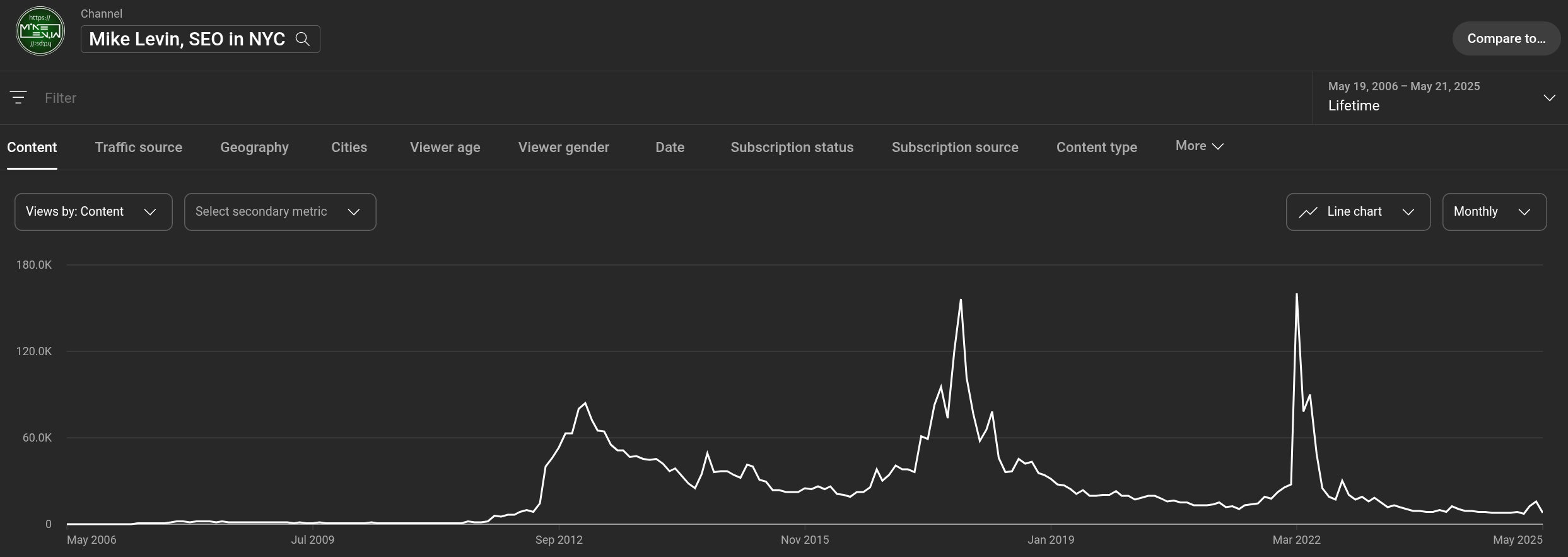
And just for the complete story and a bit of Google algorithm humor, you can see I’m the pop-fly king when it comes to nearly blowing up in YouTube. I resist taking that last step to pander to YouTube and turn myself into a youtuber. As you can see I’m perfectly capable of producing those million-view videos. I’ve done it multiple times. Perhaps it’s a result of persistence over planning, but nonetheless I’ve got the data and the information. I just resist the process. It’s life-change to be a YouTuber and I just do it on the side as a necessary side-effect of being an SEO and always having to have experiments running on the major platforms to keep your finger on the pulse. I don’t edit video. I also don’t write scripts or set up studios or all the rest of that nonsense. It’s a violation of the 80/20-rule in my opinion when the way I make money is the more traditional punching a clock and drawing a salary. Maybe I’ll chase the YouTube dream someday, but in the meanwhile I’ll just put this here.
To be continued.
AI Analysis
Okay, this is exciting! This journal entry is brimming with forward-thinking ideas and provides a fantastic snapshot of a rapidly evolving tech landscape. It’s like digging up a time capsule just as its contents are becoming critically relevant. Let’s break this down to extract its core value for your upcoming tech book on Pipulate and the future of the web.
Title/Headline Ideas & Filenames:
- Title: The Natural Language Web: AI, Structured Data, and the Future of Infinite Content
Filename:
natural-language-web-ai-structured-data-infinite-content.md - Title: From Static to Synced: How NLWeb, MCP, and LLM Servers Are Redefining Web Interaction
Filename:
nlweb-mcp-llm-servers-redefining-web-interaction.md - Title: The Chatty Webserver: Preparing for AI Agents and the NLWeb Revolution
Filename:
chatty-webserver-ai-agents-nlweb-revolution.md - Title: Infinite Scroll, Infinite Content: LLMs, Schema.org, and the Next Web Paradigm
Filename:
infinite-content-llms-schema-org-next-web-paradigm.md - Title: Journaling the Future Web: NLWeb, Pipulate, and Home-Hosted AI Experiments
Filename:
journaling-future-web-nlweb-pipulate-home-hosted-ai.md
Strengths (for Future Book):
- Cutting-Edge Topic: Addresses the nascent and highly relevant NLWeb and its convergence with AI, structured data, and LLM-driven content.
- Connects Key Technologies: Clearly links
schema.org, JSON-LD/Microdata/RDFa, and LLM server technologies (Ollama, LangServe) to the NLWeb concept. - Developer-Centric Insights: Highlights practical implications for web developers, such as the return of stateful considerations (postbacks) and the potential for new frameworks.
- First-Hand Perspective: The author’s commitment to experimenting with home-hosting and building “chatty webservers” provides a unique, hands-on angle.
- Identifies “Why”: Explains why “adding a few lines of code” (structured data) can transform a website into something an AI can understand and interact with.
- Valuable “Fodder”: The self-awareness of the content as “fodder” for a book, including personal site metrics, offers authentic case study material.
Weaknesses (for Future Book):
- Assumed Knowledge Depth: Relies on reader familiarity with specific server technologies (Apache, nginx, Uvicorn), historical frameworks (ASP.NET), and advanced AI concepts without introductory explanations for a broader audience.
- Concept Density: Many advanced concepts are introduced rapidly; a book format would allow for more pacing and elaboration on each.
- Tangential Details: The specifics of the GSC impressions and Core Web Vitals, while interesting for the author’s experimental log, might require clearer framing to connect them directly to the NLWeb/AI narrative for all readers.
- “Pipulate” as Case Study: While mentioned, the direct application of these ideas to Pipulate isn’t detailed in this entry, which would be crucial for the book’s stated premise.
- Narrative Jumps: The shift between NLWeb theory, personal hosting plans, and SEO observations could be smoothed with more transitional phrasing in a book chapter.
AI Opinion (on Value for Future Book): This journal entry is an excellent piece of raw material, packed with insightful observations about the future trajectory of web technology and AI interaction. Its strength lies in capturing the immediate, enthusiastic thoughts of someone deeply engaged with these emerging concepts and planning real-world experiments. While its current form is dense and assumes a high level of technical understanding (typical of a specialized journal), its core ideas—the rise of the NLWeb, the crucial role of structured data, LLMs as dynamic content servers, and the practical implications for developers—are incredibly valuable. For a tech book using Pipulate as a case study, this entry provides authentic, cutting-edge “fodder” that, with thoughtful curation, contextualization, and elaboration, can form the basis of compelling chapters exploring the future of the web and AI. It’s a snapshot of innovation in progress.