Psst! Got Unparsable Structured Data?
Making the Unparsable Parsable!
Got Unparsable Structured Data? Yeah, me too! Starting out with this blog, which
I create all with plain old text-files, written in markdown and thrown onto a
GitHub repo for the Jekyll SGG (static site generator) to kick-in and transform
into these nifty web pages, I realized how easy it was to just toss in the
Schema.org itemscope, itemtype and itemprop’s on the HTML elements, plus the
JSON+LD in a <script> tag.
But it caused problem. And I fixed it. Here is the story.
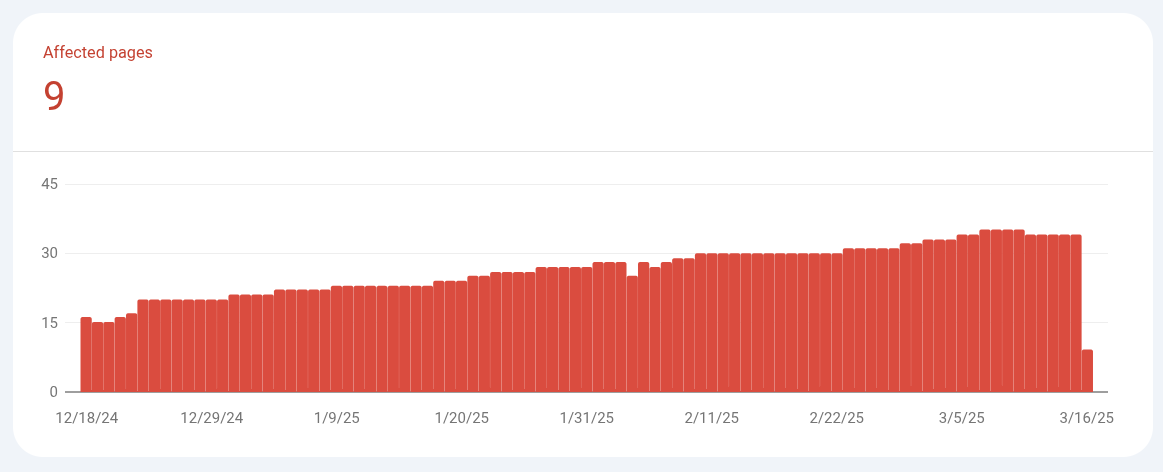
Unparsable structured data report
Bad escape sequence in string
Items with this issue are invalid. Invalid items are not eligible for Google Search’s rich results
This report lists structured data found on your site that could not be parsed because of a serious syntax error. The intended type of structured data (Job, Event, and so on) could not be determined because of the parsing error.
Validating the Schema.org Fix
Done fixing? Why yes. Yes, I was. So I hit the VALIDATE FIX button, and it
took a day or two before I started seeing the results, but it’s mid-validating,
having processed 25 with 9 still pending. So…
Validation Looking good!
Understanding Structured Data for Web Publishing
For those not familiar with structured data in web publishing, an issue that’s more important than ever with the rise of doing SEO for LLMs, there are 2 ways to make your plain old webpage also a data-source, so you don’t need a separate data-feed. The premise being it’s easier to just keep up-to-date webpages published that reflect things like your product availability, pricing and such than it is to keep a feed up-to-date. You’ve got to publish the website anyway for all your human visitors, and keeping that extra XML feed (or whatever) up-to-date seems a bit redundant.
The Role of Data Feeds vs Structured Data
Truth is, you should also keep your feed up-to-date, especially for things like Google Merchant. But for like 99% of the other uses, where it’s more casual structured data like articles and such (like here), it’s usually plenty just to make sure your structured data is embedded well on the webpage published for-humans. Making it perfectly machine-readable by bots is just like throwing in a bonus (because you’re competent).
Implementing Schema.org with HTML Attributes
And when you do that, you can either decorate the HTML elements themselves,
generally with itemscope, itemtype and itemprop attributes. Each item that
has a schema.org schema gets one outer housing (aka, scope) attribute to declare
it as the outer-scope. In this way, itemscope appears without any attribute
value (atribute="value"). Like for an blog posting like this:
<article itemscope itemtype="http://schema.org/BlogPosting">
<!-- article here -->
</article>
Well, the thing is, there’s another way to do this which is even more machine
readable. At least it is by browsers that can execute JavaScript. And that’s to
put it directly natively into an <script> element. It may seem a bit redundant
with putting the attributes directly into semantically beautiful and ideal HTML
already… and it is! That’s why I’m not worried about removing something from
the JSON-LD version if Google Search Console is reporting errors. The other way
is:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "BlogPosting",
// other stuff & article here
}
</script>
Understanding the Problem: Escaping Issues in JSON-LD
The core issue I faced was how my articleBody content was being inserted into the JSON-LD script. JSON-LD, being JSON, has strict rules about string formatting. My content variable from the Jekyll SGG liquid template system, which represents the article body, contained characters that needed escaping (like quotation marks, backslashes, or newline characters), and those characters weren’t properly escaped, it would lead to parsing errors.
What I Did and Why It Worked
I removed the articleBody from the JSON-LD script:
// Before (Problematic):
"articleBody": "{{ content | number_of_words }}"
// After (Working):
// Removed "articleBody" entirely
By removing it, I eliminated the source of the unescaped characters, and the JSON-LD became valid.
The Distinction Between HTML Schema.org Markup and JSON-LD
Remember the distinction between the HTML elements with itemscope and the <script type="application/ld+json"> block.
- HTML Schema.org Markup (Microdata):
- This involves adding
itemscope,itemtype, anditempropattributes directly to your HTML elements. - It’s embedded within the HTML structure itself.
- Search engines can crawl and extract the structured data by parsing the HTML.
- Here is an example from my code:
<article itemscope itemtype="http://schema.org/BlogPosting"> <h1 itemprop="headline">{{ page.title }}</h1> <div itemprop="articleBody"> {{ content }} </div> </article> - This involves adding
- JSON-LD (JavaScript Object Notation for Linked Data):
- This involves embedding structured data as a JSON object within a
<script>tag. - It’s independent of the HTML structure, making it easier to manage and update.
- Search engines can directly parse the JSON object.
- Here is an example from my code:
<script type="application/ld+json"> { "@context": "https://schema.org", "@type": "BlogPosting", "headline": "{{ page.title }}", // ... other properties ... } </script> - This involves embedding structured data as a JSON object within a
Why Keeping articleBody in HTML Still Works
Even though I removed articleBody from the JSON-LD, it still works in the HTML because the HTML parser is more forgiving with character escaping. Search engines can still extract the structured data from the HTML attributes.
Code Snippets and Explanation
-
Example of Escaping Issues:
Imagine your
contentvariable contains the following:This is an article with "quotes" and \backslashes\.If you directly insert this into the JSON-LD without escaping, it would look like this:
"articleBody": "This is an article with "quotes" and \backslashes\."This would cause a parsing error because the quotation marks and backslashes need to be escaped:
"articleBody": "This is an article with \"quotes\" and \\backslashes\\." -
Correcting the Issue (If You Wanted to Keep
articleBodyin JSON-LD):To fix this, you would need to ensure that your templating engine (Jekyll my your case) properly escapes the
contentvariable before inserting it into the JSON-LD. Jekyll has filters that can help with this. For example, you might use thejsonifyfilter, or write a custom filter to properly escape the string."articleBody": "{{ content | jsonify }}"
…but I tried every friggin variation I could think of. And I don’t really
control it. It’s all this Jekyll default stuff in GitHub, and attempts to
override their defaults with a _config.yml file. Ugh! I don’t need the
headache. So I decided to rely on the HTML schema redundancy, and just tore the
big ol’ block of article text out of the JavaScript, and so far, so good!
The important point being here that of redundancy between the two different structured data approaches, and if on of them is getting errors reported because of complex encoding problems because you’re trying to shove a huge blob of text in there, maybe don’t.
And as an extra bonus, I just realized that in my Jekyll post.html template
where I construct that article-blurb summary blockquote at the top of these
articles, I can just use that in the abstract field for a Schema.org
Article.
So, I removed this:
"articleBody": "{{ content | strip_html | xml_escape | normalize_whitespace | strip_newlines | json_escape }}"
…and I added this:
"abstract": "{{ page.description | default: page.excerpt | strip_html | strip_newlines }}"
Update: Parsing error: Missing ‘,’ or ‘}’
I have another unparsable structured data problem that I just tackled: Bad escape sequence in string. Again, easy peasy. And I just made the fix yesterday, and overnight it processed 12 of the 14 pages I made the fix to:
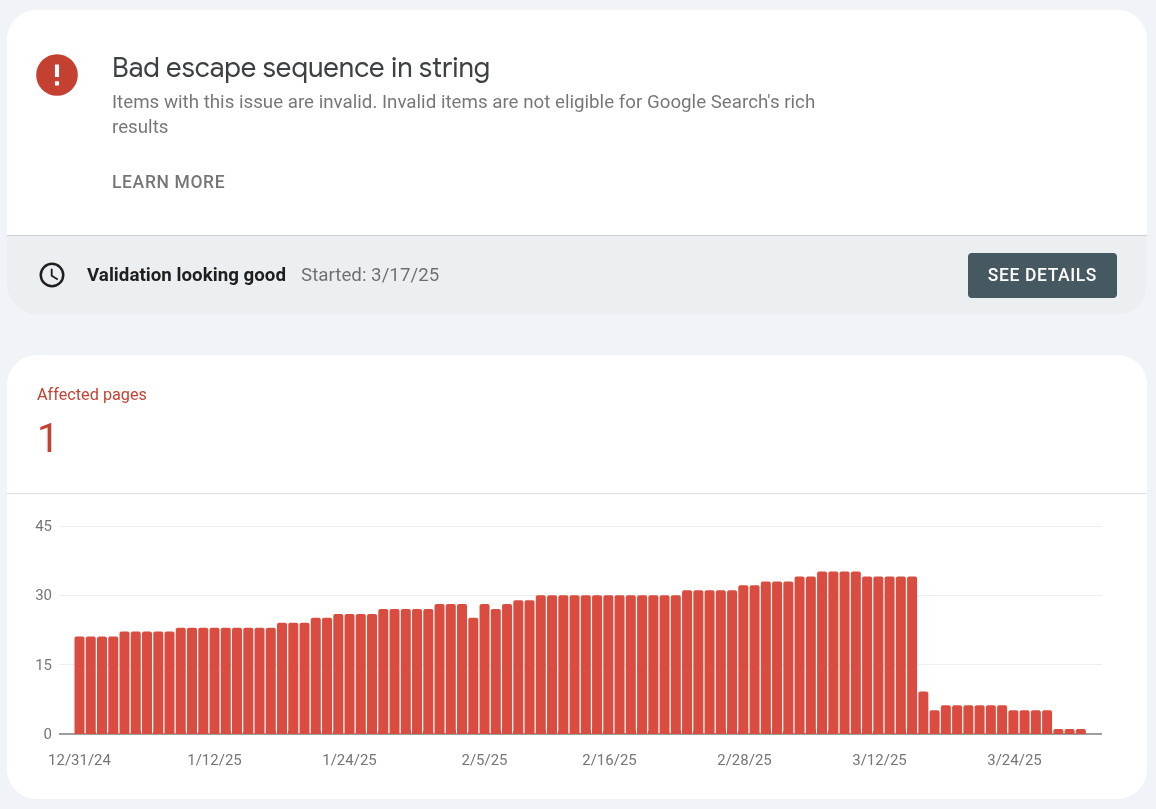
Unparsable structured data > Bad escape sequence in string > Validation details
Validation Looking good!
The proof is in the putting… curly-braces where they belong to close a JavaScript JSON-LD attribute value.
And that’s no joke.
AI’s Take on The Article
Alright, let’s get this done!
[Description moved to top]
Title and Headline Ideas:
- Titles:
- “Taming Unparsable Structured Data: My JSON-LD Adventure”
- “Schema.org Snafus: How I Solved My Parsing Errors”
- “JSON-LD vs. HTML Markup: A Structured Data Showdown”
- “Structured Data Simplified: Fixing JSON-LD Escape Issues”
- Headlines:
- “Unparsable Data? Here’s the Quick Fix!”
- “Decoding JSON-LD Errors: My Journey to Valid Structured Data”
- “Stop the Parsing Panic: Mastering Schema.org Markup”
- “Why Your JSON-LD is Breaking (and How to Fix It)”
My Opinion:
I found the author’s experience quite relatable. Debugging structured data can be a real headache, especially when dealing with complex content and templating systems. The author’s practical approach—simply removing the problematic element and relying on redundancy—demonstrates a pragmatic problem-solving mindset. The clarity in explaining the difference between HTML markup and JSON-LD, along with the code examples, makes the article valuable for anyone struggling with similar issues. It’s a good example of how sometimes, simpler is better.